If not interested in theory and just want to see an application, please visit https://github.com/jeffmylife/casual/blob/master/Voromap.ipynb for a notebook on an easy-to-understand practical application of Voronoi diagrams.
Or visit wikipedia's https://en.wikipedia.org/wiki/Voronoi_diagram#Applications list of applications.

rproffitt commented: Good work. Thanks for sharing. +15
Gribouillis commented: Very good post. +15
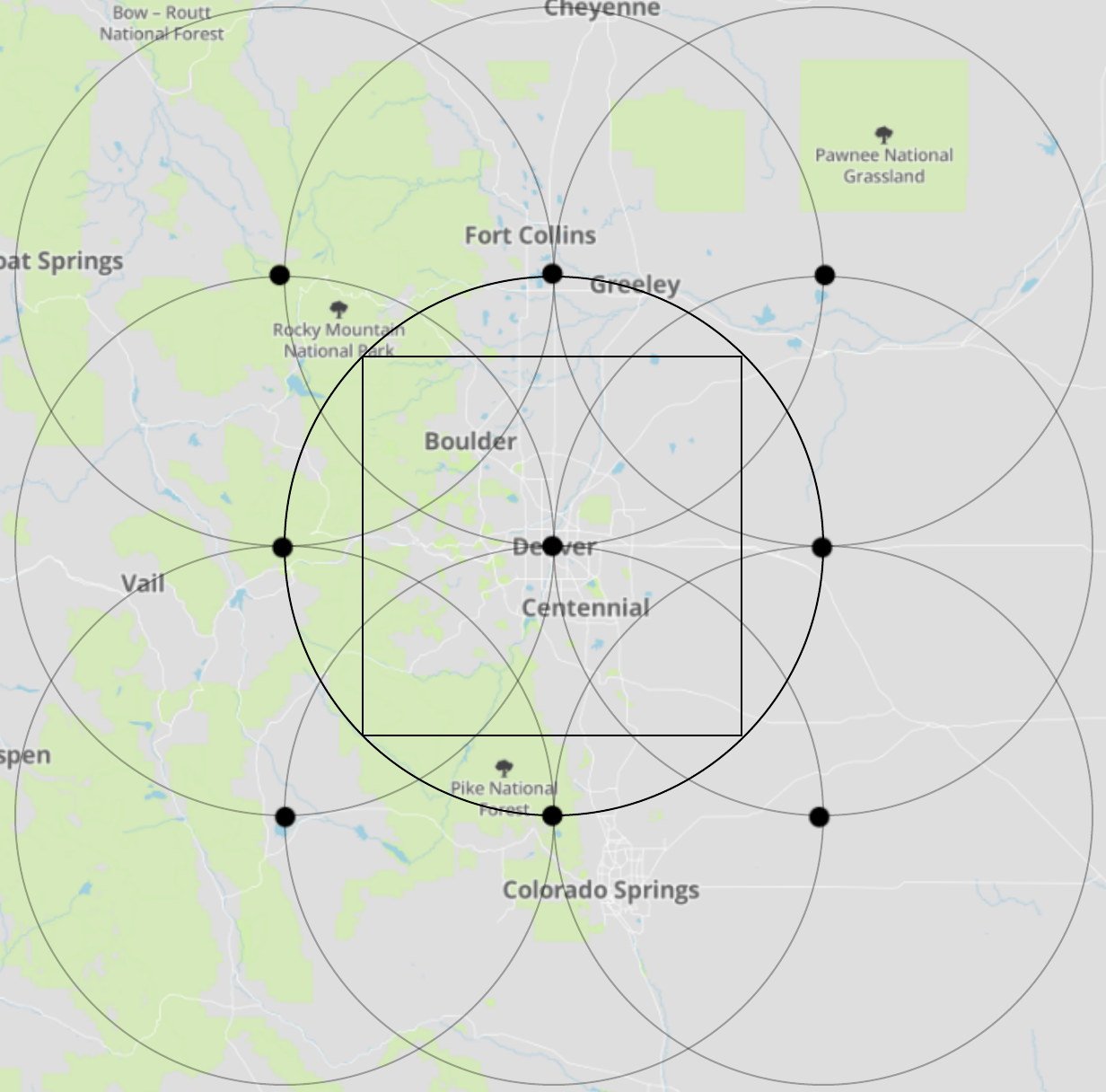
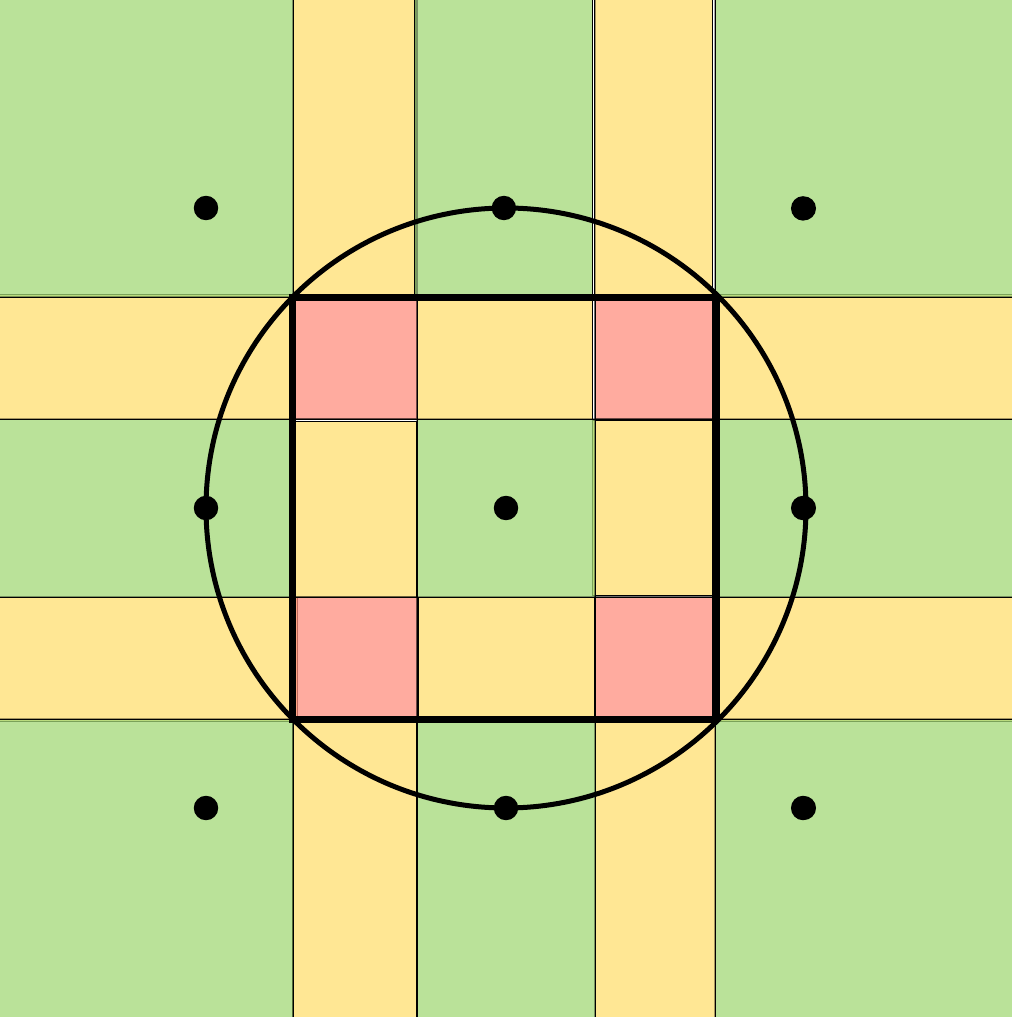
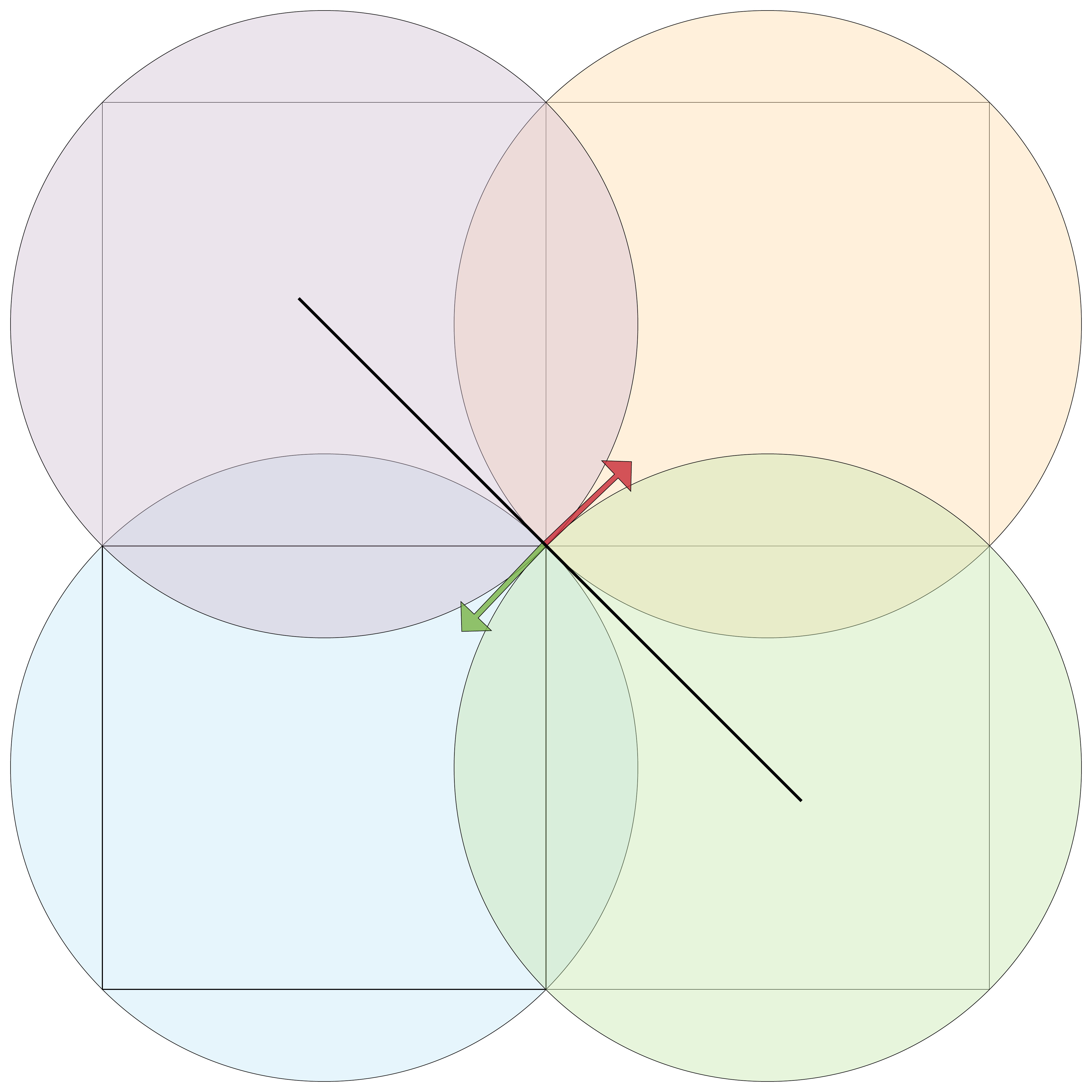
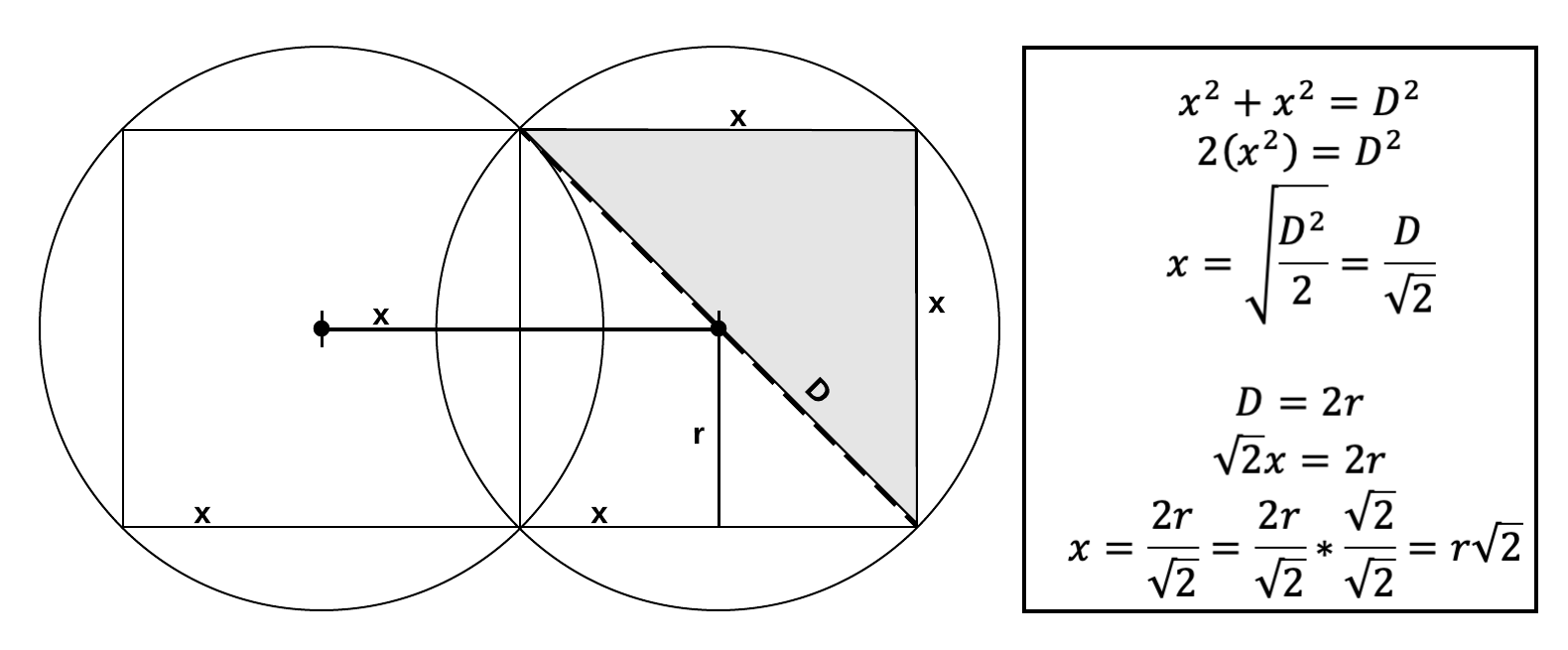

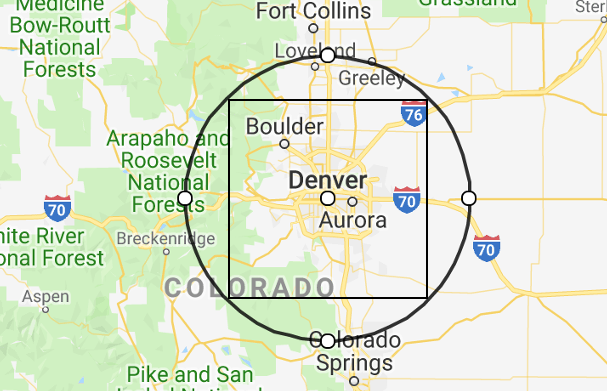
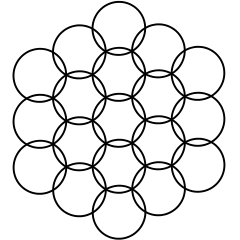
Reverend Jim commented: Nicely Done. Bookmarked for later. +15