I was searching for Paris Olympics ticket prices for tennis games recently. The official website directs you to a PDF document containing ticket prices and venues for all the games. However, I found the PDF document to be very hard to navigate. To make things easier, I developed a chatbot to search this PDF document and answer my queries in natural language. And this is what I am going to share in this article.
I used the OpenAI API to create document embeddings (convert documents to numeric values) and the Python LangChain library as the orchestration framework to develop this chatbot.
So, let's begin without ado.
Installing and Importing Required Libraries
The following script installs the libraries required to run scripts in this article.
!pip install -U langchain
!pip install langchain-openai
!pip install pypdf
!pip install faiss-cpu
The script below imports required libraries.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain_core.documents import Document
import os
Generate Default Responses from Chat-GPT
Let's first generate some responses from Chat-GPT without augmenting its knowledge base with information about the Paris Olympics ticket price.
In a Python application, you will use the OpenAI API key to generate Chat-GPT responses. You can retrieve your API key by signing up for OpenAI API.
You can save your API key in an environment variable and retrieve it in your Python application via the following script.
openai_key = os.environ.get('OPENAI_KEY2')
Next, you must create an object of the ChatOpenAI class, pass it your API key, the model name (gpt-4 in this case), and the temperature value (between 0 and 1). A higher temperature value allows the model to be more creative.
llm = ChatOpenAI(
openai_api_key = openai_key ,
model = 'gpt-4',
temperature = 0.5
)
To generate a response, call the invoke() method using the model object and pass it your input query.
result = llm.invoke("You are a comedian, tell a Joke about maths.")
print(result.content)
Output:
Why was the math book sad?
Because it had too many problems!
You can use the LangChain ChatPromptTemplate class to create a chatbot. The from_messages() method in the following script tells LangChain that we want to execute the conversation in message format. In this case, you must specify the value for the user attribute. The system attribute is optional.
prompt = ChatPromptTemplate.from_messages([
("system", '{assistant}'),
("user", "{input}")
])
Next, you must create a chain combining your prompt with the LLM. You can use the pipe operator (|) to create a chain.
Finally, you can execute the message chain using the invoke() method. You must pass values for the attributes defined in your prompt (system and user in our case).
You can print LLM's response using the content attribute of the response object.
chain = prompt | llm
result = chain.invoke(
{"assistant": "You are a comedian",
"input": "Tell a joke about mathematics"}
)
print(result.content)
Output:
Why was the math book sad?
Because it had too many problems!
The LangChain also provides a StrOutputParser object that you can use to directly retrieve string responses without using the content attribute, as shown in the script below.
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
result = chain.invoke(
{"assistant": "You are a comedian",
"input": "Tell a joke about mathematics"}
)
print(result)
Output:
Why was the math book sad?
Because it had too many problems!
Chat-GPT can only generate correct responses if it contains the answer in its knowledge base. Since the latest model of GPT-4 was trained on the data until December 2023, it will not be able to return factual information about the events of 2024. Let's verify this.
In the following prompt, I asked Chat-GPT to tell me the ticket prices for tennis games in the Paris Olympics 2024.
result = chain.invoke(
{"assistant": "You are a ticket receptionist",
"input": "What is the lowest ticket price for tennis games in Paris Olympics 2024?"})
print(result)
Output:

The above response shows that Chat-GPT does not know the Paris Olympics ticket prices.
In the next section, we will provide Chat-GPT with the ticket information using a retrieval augmented generation technique (RAG), and you will see that it generates correct responses.
RAG for Augmented Response Generation from Chat-GPT
Retrieval augmented generation (RAG) works in three steps.
- Split and create embeddings for the documents containing the knowledge base you want to search.
- Based on the user query, use similarity search to find documents most likely to contain a response for the query.
- Pass the user query and the matched document in a prompt to an LLM (Chat-GPT in our case) to generate a response.
Let's see how we can do this.
Splitting and Embedding Ticket Price Information Document
The following script imports the PDF document containing ticket price information and splits it into multiple pages.
loader = PyPDFLoader("https://tickets.paris2024.org/obj/media/FR-Paris2024/ticket-prices.pdf")
docs = loader.load_and_split()
Next, you can use any embedding technique to convert documents to numeric format. We convert documents to numeric embeddings since matching numbers is easier than documents.
Many advanced embedding techniques exist. However, OpenAI embeddings are the most accurate. The following script creates a vector database storing the vector embeddings for all the pages in the input PDF document.
embeddings = OpenAIEmbeddings(openai_api_key = openai_key)
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
Question Answering with Chatbot
To implement question answering, we will create a ChatPromptTemplate object, passing the input query along with the context information retrieved from the vector database. The context information contains the answer to our query.
We will create a create_stuff_documents_chain chain that can generate LLM responses based on the context retrieved from documents.
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
Question: {input}
Context: {context}
"""
)
document_chain = create_stuff_documents_chain(llm, prompt)Let's first run our chain with the hard-coded context. In the following script, we ask a question and pass the context manually.
document_chain.invoke({
"input": "What is the lowest ticket price for tennis games in Paris Olympics 2024?",
"context": [Document(page_content = "The ticket prices for tennis games are 15, 10, 25 euros")]
})Output:
'The lowest ticket price for tennis games in Paris Olympics 2024 is 10 euros.'The Chat-GPT was intelligent enough to infer from the context that the lowest price is 10 euros.
However, we do not want to pass the context information manually. This kills the whole purpose of a chatbot. Instead, we want to provide the context information by searching the vector database containing the knowledge base. Then, we pass the searched context along with the input query to an LLM.
To do so, you can use your vector database's retriever() class and pass it along with the document_chain object to the create_retrieval_chain() class object.
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
Next, you can call the invoke() method from your retrieval chain to generate the final response. This method will pass the query to the vector database, which returns the most similar document and stores it in the context variable. This context variable, along with the input from the retrieval chain, is passed to the document_chain, which returns the final response.
The following script implements the method to generate the final response.
def generate_response(query):
response = retrieval_chain.invoke({"input": query})
print(response["answer"])
Let's now ask some questions about the prices of tickets for the tennis games. The page for the tennis games' ticket prices looks like this.
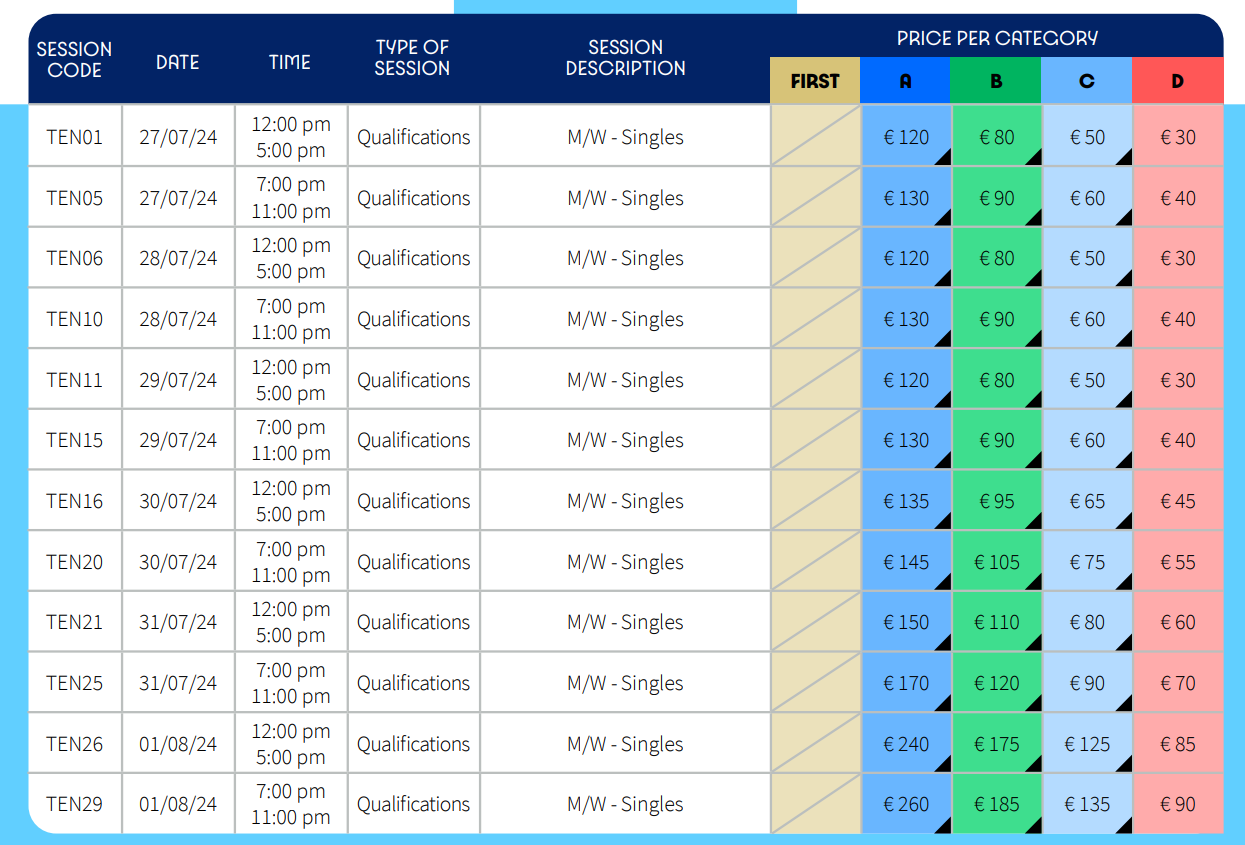
Let's first ask about the lowest-priced ticket.
query = "What is the lowest ticket price for tennis games?"
generate_response(query)
Output:
The lowest ticket price for tennis games is €30.The above response is correct, as shown in the price table.
Let's see another example. The following output shows that the model correctly returns the category for the lowest-priced ticket.
query = "What is the category for the lowest ticket price for tennis games?"
generate_response(query)Output:
The category for the lowest ticket price for tennis games is D.You can also ask a more complicated question such as the following, and you will see that the model will generate a correct response.
query = "What is the maximum price for category B for men's single tennis games for non-medal games?"
generate_response(query)Output:
The maximum price for category B for men's single tennis games for non-medal games is €185.I tried asking further questions about other sports, game venues, etc., and the model always returned the correct response.
Conclusion
The retrieval augmented generation (RAG) technique has made it easy to develop customized chatbots on your data. In this tutorial, you saw how to develop a chatbot that can provide ticket information for all the games in the Paris Olympics. You can use the same approach to develop chatbots that query other data types such as PDFs, websites, text documents, etc.