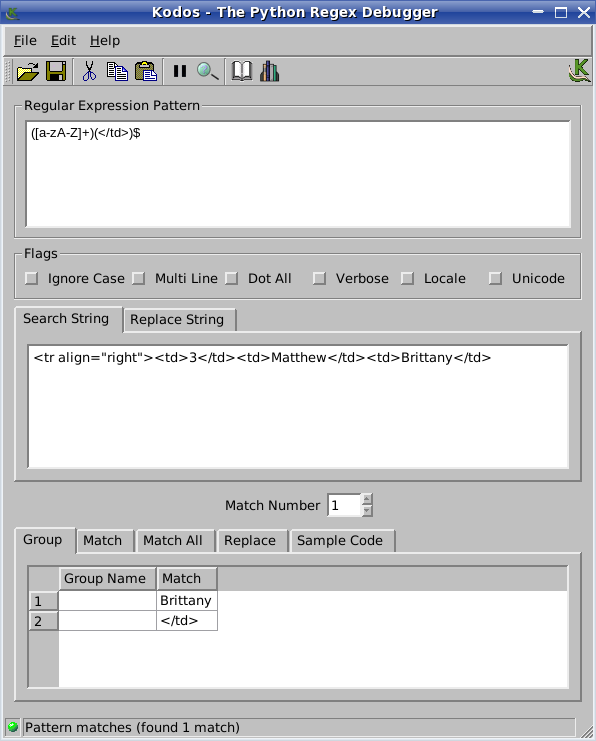
I am using the following code to extract second name from the html having following kind of lines -
<tr align="right"><td>3</td><td>Matthew</td><td>Brittany</td>
So, I want to extract "Brittany" from the above line
for line in f:
match3 = re.search(r'$([a-zA-Z]+)(</td>)',line)
if match3:
print match3.group(1)But this ain't working. Please help.