I recently worked on a research project where I had to find the inter-annotator agreement for tweets annotated by three annotators.
Inter annotator agreement refers to the degree of agreement between multiple annotators. The quality of annotated (also called labeled) data is crucial to developing a robust statistical model. Therefore, I wanted to find the agreement between multiple annotators for tweets.
The Dataset
The data set consists of 50 tweets. The annotator’s task was to assign three emotions from a total of 9 emotions to each of the tweets. The annotators have to rank the tweets according to what they think is the most likely, the second most likely, and the third most likely emotion.
The final dataset consists of 50 rows with nine columns. The cell values can be:
- 1 for the most likely emotion,
- 2 for the second most likely emotion,
- 3 for the third most likely emotion).
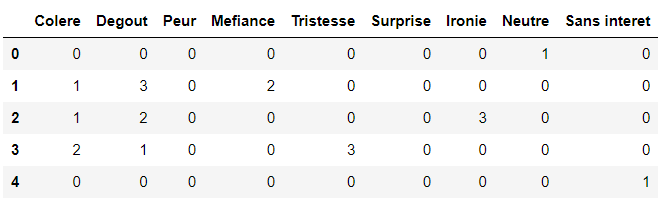
Here is what the dataset looks like. The column headers contain emotion names in French.
Evaluation Approach for Inter Annotator Agreement
Some statistical metrics exist for evaluating inter-annotator understanding, e.g., Kendal tao distance, Fleiss kappa, etc.
However, I was initially interested in more simplistic metrics such as finding:
- The number of annotations where there is a complete agreement between the three annotators for any emotion rank.
- The number of annotations where all annotators agree on a particular emotion rank
- The number of annotations where all annotators assign at least one rank to a specific emotion.
- The number of annotations where at least two of the three annotators agree on any emotion rank
- The number of annotations where at least two of the three annotators agree on a particular emotion rank
- The number of annotations where at least two of the three annotators assign at least one rank to a specific emotion.
I implemented the five tasks mentioned above into two methods.
The first method finds the inter-annotator agreement for three annotators for the first three tasks from the above list.
The second method finds the inter-annotator agreement for two of the three annotators for task number 4-5 in the above list.
Finding Inter-Annotator Agreement for Three Annotators
Here is the Python code for the method that finds inter-annotator agreement between three annotators:
def get_agreement_3(df1, df2, df3, rank, agreement):
matches = []
## if the three annototars assign the same rank to a record
if agreement == 'full':
for i in range(df1.shape[0]):
for j in range(df1.shape[1]):
row ={'index':0,'1':0, '2':0, '3':0, 'emotion':''}
## inter annotator agreement for all the ranks
if rank > 3 and df1.values[i,j] >0:
if (df1.values[i,j] == df2.values[i,j] == df3.values[i,j]):
row[str(df1.values[i,j])] = 3
row['emotion'] = df1.columns[j]
row['index'] = i
matches.append(row.copy())
## inter annotator agreement for a specific rank
elif (df1.values[i,j] == rank):
if (df1.values[i,j] == df2.values[i,j] == df3.values[i,j]):
row[str(rank)] = 3
row['emotion'] = df1.columns[j]
row['index'] = i
matches.append(row.copy())
return matches
## if the three annotators assign at least one of the
## three emotion ranks to a record
elif agreement == 'partial':
for i in range(df1.shape[0]):
for j in range(df1.shape[1]):
row ={'index':0, 'annot_values':'', 'emotion':''}
## inter annotator agreement for all the ranks
if rank > 3 and (df1.values[i,j] >0) and (df2.values[i,j] >0) and (df3.values[i,j] >0):
row['annot_values'] = str(df1.values[i,j]) + '-' + str(df2.values[i,j]) + '-' + str(df3.values[i,j])
row['emotion'] = df1.columns[j]
row['index'] = i
matches.append(row.copy())
return matchesThe get_agreement_3() method in the above script accepts five parameter values: the three Pandas dataframes, the rank value, and the type of match to perform. The dataframes contain the annotation values.
I iterate through all the records in the three Pandas dataframes and match the corresponding values.
In the case of a full agreement, when the rank value is greater than 3, the get_agreement_3() method returns a list of dictionaries. Each dictionary in the list contains the following information:
- The rank assigned to a match.
- The name of the emotion for the match.
- The index or the record number for which the match is found.
For a better view, we can convert the list of dictionaries returned by the get_agreement_3() method into a Pandas dataframe. We can then extract information such as the number and percentage of matches. The following script does that.
agreement = 'full'
print("Overall Full Match Result for Three Annotators")
print("==========================")
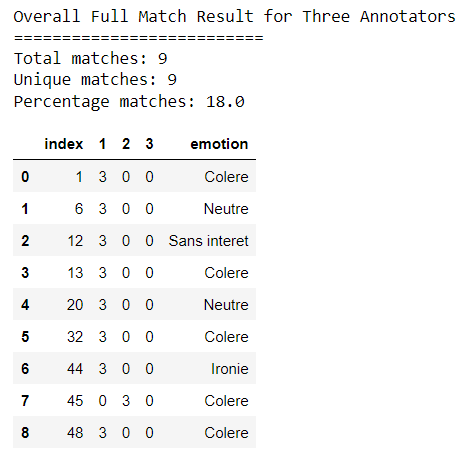
agreement_dic= get_agreement_3(file_50_1_JC, file_50_1_HL, file_50_1_SB, 99, agreement)
df = pd.DataFrame.from_records(agreement_dic)
print('Total matches:',df.shape[0])
print('Unique matches:',df['index'].nunique())
print('Percentage matches:', (df['index'].nunique()/file_50_1_JC.shape[0] * 100))
df.head(50)Output:
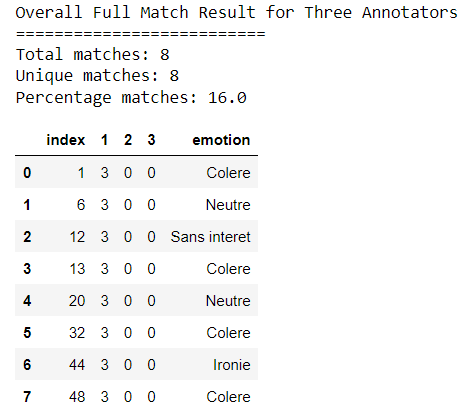
If the rank is less than 3, the matches for that specific rank are returned. The following script finds the number of full matches for rank 1.
agreement = 'full'
print("Overall Full Match Result for Three Annotators")
print("==========================")
agreement_dic= get_agreement_3(file_50_1_JC, file_50_1_HL, file_50_1_SB, 1, agreement)
df = pd.DataFrame.from_records(agreement_dic)
print('Total matches:',df.shape[0])
print('Unique matches:',df['index'].nunique())
print('Percentage matches:', (df['index'].nunique()/50 * 100))
df.head(50)Output:
In case of partial agreement, the returned list of dictionaries consists of matches where all annotators assign at least one rank to a specific emotion. The following script tests this scenario:
agreement = 'partial'
print("Overall Partial Match Results for Three Annotators")
print("==========================")
agreement_dic = get_agreement_3(file_50_1_JC, file_50_1_HL, file_50_1_SB, 99, agreement)
df = pd.DataFrame.from_records(agreement_dic)
print('Total matches:',df.shape[0])
print('Unique matches:',df['index'].nunique())
print('Percentage matches:', (df['index'].nunique()/50 * 100))
df.head(50)Output:

Finding Inter-Annotator Agreement Between Two of Three Annotators
Finding the inter-annotator agreement between two of three annotators is very similar to finding the agreement between two annotators.
You only have to add a condition that returns a match if two of the three annotators agree. I implemented a different method for that, as shown in the following script:
def get_agreement2_3(df1, df2, df3, rank, agreement):
matches = []
## if two of the three annototars assign the same rank to a record
if agreement == 'full':
for i in range(df1.shape[0]):
for j in range(df1.shape[1]):
row ={'index':0, 'annot_values':'' , 'emotion':''}
## inter annotator agreement for all the ranks
if rank > 3:
if (df1.values[i,j] >0) and ((df1.values[i,j] == df2.values[i,j]) or (df1.values[i,j] == df3.values[i,j])):
row['annot_values'] = str(df1.values[i,j]) + '-' + str(df2.values[i,j]) + '-' + str(df3.values[i,j])
row['index'] = i
row['emotion'] = df1.columns[j]
matches.append(row.copy())
elif (df2.values[i,j] >0) and (df2.values[i,j] == df3.values[i,j]):
row['annot_values'] = str(df1.values[i,j]) + '-' + str(df2.values[i,j]) + '-' + str(df3.values[i,j])
row['index'] = i
row['emotion'] = df2.columns[j]
matches.append(row.copy())
## inter annotator agreement for a specific rank
elif (df1.values[i,j] == rank) and ((df1.values[i,j] == df2.values[i,j]) or (df1.values[i,j] == df3.values[i,j])):
row['annot_values'] = str(df1.values[i,j]) + '-' + str(df2.values[i,j]) + '-' + str(df3.values[i,j])
row['index'] = i
row['emotion'] = df2.columns[j]
matches.append(row.copy())
elif (df2.values[i,j] == rank) and (df2.values[i,j] == df3.values[i,j]):
row['annot_values'] = str(df1.values[i,j]) + '-' + str(df2.values[i,j]) + '-' + str(df3.values[i,j])
row['index'] = i
row['emotion'] = df2.columns[j]
matches.append(row.copy())
elif agreement == 'partial':
for i in range(df1.shape[0]):
for j in range(df1.shape[1]):
row ={'index':0, 'annot_values':'' , 'emotion':''}
## inter annotator agreement for all the ranks
if (df1.values[i,j] >0 and df2.values[i,j] >0) or (df1.values[i,j] > 0 and df2.values[i,j] >0) or (df2.values[i,j] >0 and df3.values[i,j] >0):
row['annot_values'] = str(df1.values[i,j]) + '-' + str(df2.values[i,j]) + '-' + str(df3.values[i,j])
row['index'] = i
row['emotion'] = df1.columns[j]
matches.append(row.copy())
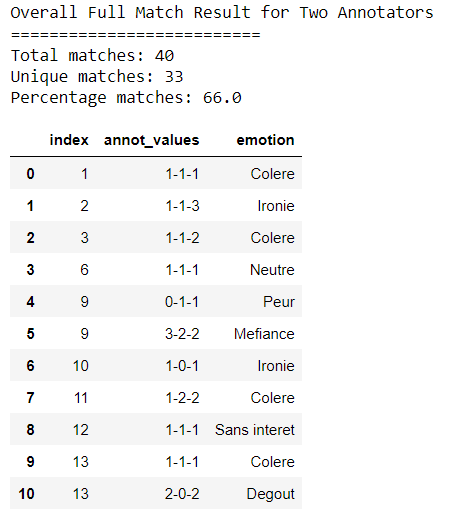
return matchesThe following script tests the scenario where two of the three annotators agree on a rank:
agreement = 'full'
print("Overall Full Match Result for Two Annotators")
print("==========================")
agreement_dic= get_agreement2_3(file_50_1_JC, file_50_1_HL, file_50_1_SB, 99, agreement)
df = pd.DataFrame.from_records(agreement_dic)
print('Total matches:',df.shape[0])
print('Unique matches:',df['index'].nunique())
print('Percentage matches:', (df['index'].nunique()/50 * 100))
df.head(50)Output:
Similarly, the following script tests the scenario for the scenario where two of the three annotators agree on a specific rank:
agreement = 'full'
print("Overall Full Match Result for Two Annotators")
print("==========================")
agreement_dic= get_agreement2_3(file_50_1_JC, file_50_1_HL, file_50_1_SB, 1, agreement)
df = pd.DataFrame.from_records(agreement_dic)
print('Total matches:',df.shape[0])
print('Unique matches:',df['index'].nunique())
print('Percentage matches:', (df['index'].nunique()/50 * 100))
df.head(50)Output:
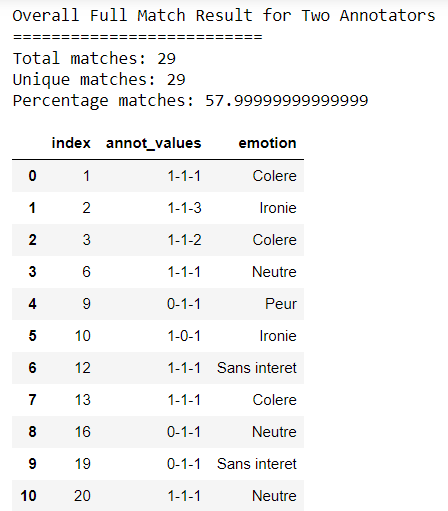
Finally, the following script returns matches where two of the three annotators partially agree on an emotion rank.
agreement = 'partial'
print("Overall Full Match Result for Two Annotators")
print("==========================")
agreement_dic= get_agreement2_3(file_50_1_JC, file_50_1_HL, file_50_1_SB, 99, agreement)
df = pd.DataFrame.from_records(agreement_dic)
print('Total matches:',df.shape[0])
print('Unique matches:',df['index'].nunique())
print('Percentage matches:', (df['index'].nunique()/50 * 100))
df.head(50)Output:
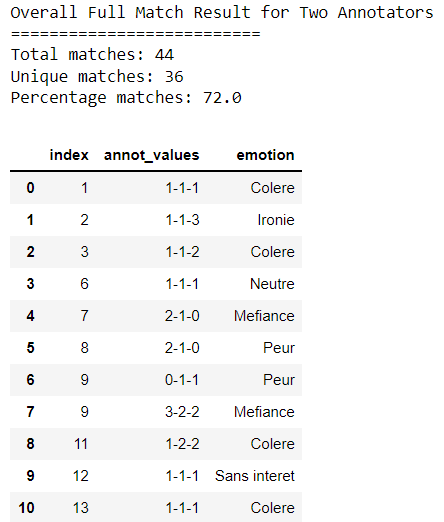
Though the methods get_agreement_3() and get_agreement2_3() have a lot in common and can be implemented as one method, I kept them separate for the sake of the clarity of the script.
I would like to know your thoughts on this approach. Feel free to make any suggestions or improvements that you might have.