On September 25, 2024, Meta released the Llama 3.2 series of multimodal models. The models are lightweight yet extremely powerful for image-to-text and text-to-text tasks.
In this article, you will learn how to use the Llama 3.2 Vision Instruct model for general image analysis, graph analysis, and facial sentiment prediction. You will see how to use the Hugging Face Inference API to call the Llama 3.2 Vision Instruct model.
The results are comparable with the proprietary Claude 3.5 Sonnet model as explained in this article.
So, let's begin without ado.
Importing Required Libraries
We will call the Llama 3.2 Vision Instruct model using the Hugging Face Inference API. To access the API, you need to install the following library.
pip install huggingface_hub==0.24.7The following script imports the required libraries into your Python application.
import os
import base64
from IPython.display import display, HTML
from IPython.display import Image
from huggingface_hub import InferenceClient
import requests
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as pltA Basic Image Analysis Example with Llama 3.2 Vision Instruct Model
Let's first see how to analyze an image using the Llama 3.2 vision instruct model using the Hugging Face Inference API.
We will analyze the following image.
image_url = r"https://healthier.stanfordchildrens.org/wp-content/uploads/2021/04/Child-climbing-window-scaled.jpg"
Image(url=image_url, width=600, height=600)
Output:

To analyze an image using the Hugging Face Inference, you must first create an object of the InferenceClient class from the huggingface_hub module. You must pass your Hugging Face access token to the InferenceClient class constructor.
Next, call the chat_completion() method on the InferenceClient object (llama3_2_model_client in the following script) and pass it the Hugging Face model ID, the model temperature, and the list of messages.
In the following script, we pass one user message with the image we want to analyze and the text query.
The chat_completion() function returns the response based on the image and the query, which you can retrieve using the response.choices[0].message.content.
In the script below, we simply ask the Meta Llama 3.2 Vision Instruct model to describe the image in a single line.
hf_token = os.environ.get('HF_TOKEN')
llama3_2_model_client = InferenceClient(token=hf_token)
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
query = "Describe the image please in one line please!"
response = llama3_2_model_client.chat_completion(
model=model_id,
temperature = 0,
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url}},
{"type": "text", "text": query},
],
}
],
max_tokens=1024,
)
print(response.choices[0].message.content)
Output:
A young child with blonde hair and blue striped pajamas is climbing on a wicker chair in front of a window.The above output shows that the model describes the image precisely.
Now that you know how to analyze an image using the Meta Llama 3.2 Vision Instruct model and the Hugging Face Inference API, let's define a utility function analyze_image() that takes in the user query and the image_url and returns the response answering the query related to the image.
In the script below, we ask the model if he sees any potentially dangerous situation in the image and how to prevent it. The response shows that the model correctly analyzes the image and suggests potential prevention measures.
def analyze_image(query, image_url):
response = llama3_2_model_client.chat_completion(
model=model_id,
temperature = 0,
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url}},
{"type": "text", "text": query},
],
}
],
max_tokens=1024,
)
return response.choices[0].message.content
query = "You are a baby sitter. Do you see any dangerous sitation in the image? If yes, how to prevent it?"
image_url = r"https://healthier.stanfordchildrens.org/wp-content/uploads/2021/04/Child-climbing-window-scaled.jpg"
response = analyze_image(query, image_url)
print(response)
Output:

Overall, the Meta Llama 3.2 Vision Instruct seems capable of general image analysis and performs at par with advanced proprietary models such as GPT-4o and Claude 3.5 Sonnet.
Graph Analysis
Let's see how well the llama 3.2 Vision Instruct performs for graph analysis tasks.
We will analyze the following bar plot, which displays Government gross debts as a percentage of GDPs for the European countries in 2023.
image_url = r"https://globaleurope.eu/wp-content/uploads/sites/24/2023/12/Folie2.jpg"
Image(url=image_url, width=600, height=600)
Output:
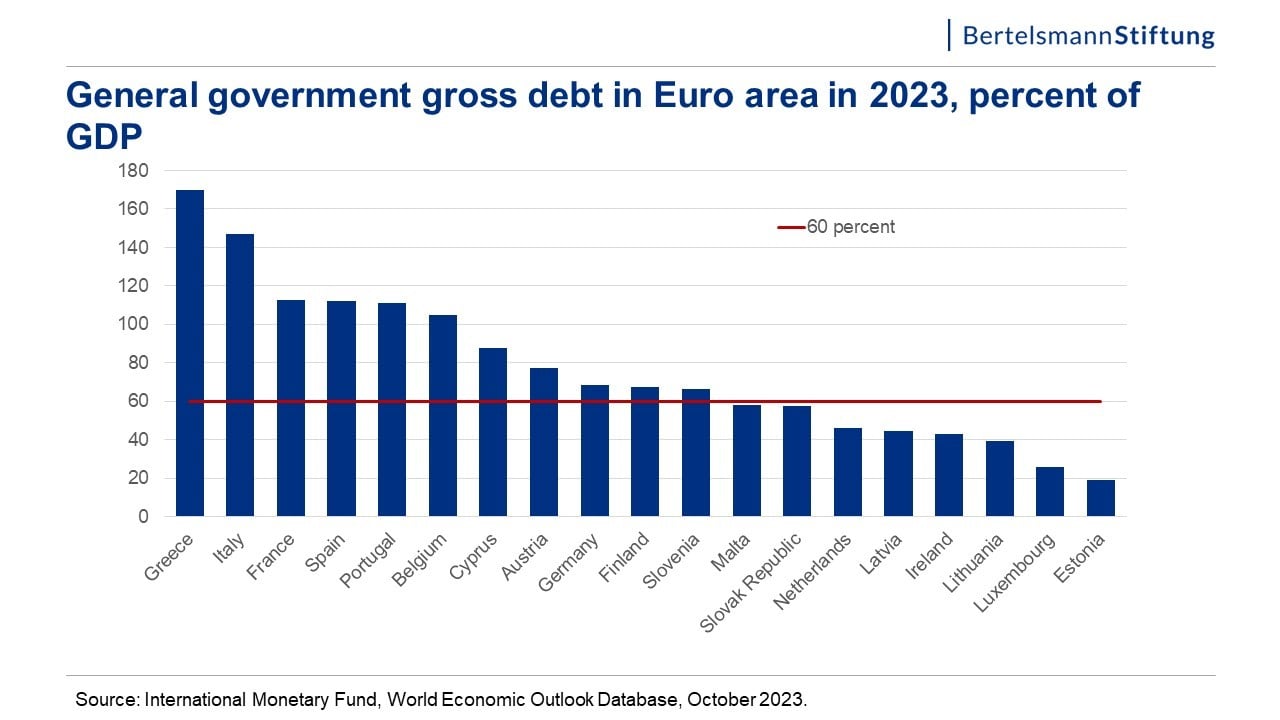
Let's just ask the model to summarize the plot.
query = "You are an expert graph and visualization expert. Can you summarize the graph?"
response = analyze_image(query, image_url)
print(response)
Output:

The above output shows that the model provides detailed insights into different aspects of the information in the bar plot.
Let's ask a slightly tricky question. We will ask the model to convert the bar plot into a table.
query = "You are an expert graph and visualization expert. Can you convert the graph to table such as Country -> Debt?"
response = analyze_image(query, image_url)
print(response)
Output:

The above output shows that the model's conversions were not precise. For example, the plot shows that Greece's GDP debt percentage is around 170%. However, the model shows it as 180%. In fact, the model shows the values in units of 10s.
On the other hand, the Claude 3.5 sonnet provided exact values.
Image Sentiment Prediction
Let's test the Llama 3.2 Vision Instruct model for the image sentiment prediction task. We will predict the facial sentiment expressed in the following image.
image_url = r"https://www.allprodad.com/wp-content/uploads/2021/03/05-12-21-happy-people.jpg"
Image(url=image_url, width=600, height=600)Output:

Run the following script to print the facial sentiment.
query = "You are helpful psychologist. Can you predict facial sentiment from the input image"
response = analyze_image(query, image_url)
print(response)Output:
Based on the image, the individual appears to be smiling, which is a common indicator of happiness or positive sentiment. The person's facial expression suggests that they are feeling content or joyful.The above output shows that the model correctly predicted the facial sentiment in the image.
Analyzing Multiple Images
Like the advanced vision models like GPT-4o and Claude 3.5 Sonnet, you can also analyze multiple images using the Llama 3.2 Vision Instruct model.
We will compare the following two images using the Llama 3.2 Vision Instruct model.
# URLs of the images
image_url1 = r"https://www.allprodad.com/wp-content/uploads/2021/03/05-12-21-happy-people.jpg"
image_url2 = r"https://www.shortform.com/blog/wp-content/uploads/2023/12/sad-woman-looking-down-eyes-slightly-closed-750x350.jpg"
# Fetch the images from the URLs
response1 = requests.get(image_url1)
response2 = requests.get(image_url2)
# Open the images using Pillow
img1 = Image.open(BytesIO(response1.content))
img2 = Image.open(BytesIO(response2.content))
# Create a figure to display the images side by side
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
# Display the first image
axes[0].imshow(img1)
axes[0].axis('off') # Hide axes
# Display the second image
axes[1].imshow(img2)
axes[1].axis('off') # Hide axes
# Show the plot
plt.tight_layout()
plt.show()
Output:

To analyze multiple images, you must add the images to the content list of the user messages, as shown in the following script.
The script below defines the analyze_multiple_images() function that accepts a text query and two images and answers the query related to both images.
def analyze_multiple_images(query, image1_url, image2_url):
response = llama3_2_model_client.chat_completion(
model=model_id,
temperature = 0,
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image1_url}},
{"type": "image_url", "image_url": {"url": image2_url}},
{"type": "text", "text": query},
],
}
],
max_tokens=1024,
)
return response.choices[0].message.content
query = "You are helpful psychologist. Can you explain all the differences in the two images?"
response = analyze_multiple_images(query, image_url1, image_url2)
print(response)
The above script attempts to find all the differences between the two input images.
Output:

The output shows that Llama 3.2 Vision Instruct can find most of the differences between the two images, and its findings are very close to those of the Claude 3.5 sonnet model.
Conclusion
Meta Llama 3.2 Vision Instruct is a lightweight yet extremely powerful model for text-to-text and image-to-text tasks. It is open-source, and you can use it for free using the Hugging Face Inference API.
In this article, you saw how to use the Llama 3.2 Vision Instruct model for image analysis tasks such as graph analysis, sentiment prediction, etc. I suggest you try the Llama 3.2 Vision Instruct model for your image-to-text and text-to-text tasks and share your feedback.