#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define TRAINING_LIST "./rc/training.list"
#define TRAINING_FILE "./training_set/%s"
#define TEST_PATH "./test_set/%s"
#define PREDICTION_FILE "./prediction.txt"
#define FEATURE_FILE "./feat/features.txt"
#define MAX_RATINGS 100480508 // Ratings in entire training set (+1)
#define MAX_CUSTOMERS 480190 // Customers in the entire training set (+1)
#define MAX_MOVIES 17771 // Movies in the entire training set (+1)
#define MAX_FEATURES 64 // Number of features to use
#define MIN_EPOCHS 120 // Minimum number of epochs per feature
#define MAX_EPOCHS 200 // Max epochs per feature
#define MIN_IMPROVEMENT 0.0001 // Minimum improvement required to continue current feature
#define INIT 0.1 // Initialization value for features
#define LRATE 0.001 // Learning rate parameter
#define K 0.015 // Regularization parameter used to minimize over-fitting
#define HASH_SIZE 54321
typedef unsigned char BYTE;
struct Movie
{
int RatingCount;
int RatingSum;
double RatingAvg;
double PseudoAvg; // Weighted average used to deal with small movie counts
};
struct Customer
{
int CustomerId;
int RatingCount;
int RatingSum;
};
struct Data
{
int CustId;
short MovieId;
char Rating;
float Cache;
};
struct Hash
{
int CustId;
int RunningId;
};
class Engine
{
private:
int m_nRatingCount; // Current number of loaded ratings
Data m_aRatings[MAX_RATINGS]; // Array of ratings data
Movie m_aMovies[MAX_MOVIES]; // Array of movie metrics
Customer m_aCustomers[MAX_CUSTOMERS]; // Array of customer metrics
float m_aMovieFeatures[MAX_FEATURES][MAX_MOVIES]; // Array of features by movie (using floats to save space)
float m_aCustFeatures[MAX_FEATURES][MAX_CUSTOMERS]; // Array of features by customer (using floats to save space)
int m_nCustomers;
Hash* m_aCustomerHash[HASH_SIZE];
int m_nCustomerHashSize[HASH_SIZE];
int m_nCustomerHashPos[HASH_SIZE];
inline double PredictRating(short movieId, int custId, int feature, float cache, bool bTrailing=true);
inline double PredictRating(short movieId, int custId);
bool ReadNumber(char* pwzBufferIn, int nLength, int &nPosition, char* pwzBufferOut);
bool ParseInt(char* pwzBuffer, int nLength, int &nPosition, int& nValue);
bool ParseFloat(char* pwzBuffer, int nLength, int &nPosition, float& fValue);
int GetCustomerHashId( int CustId );
int GetCustomerId( int CustId );
public:
Engine(void);
~Engine(void) { };
void CalcMetrics();
void CalcFeatures();
void SaveFeatures();
void LoadHistory();
void ProcessTest(char* pwzFile);
void ProcessFile(char* pwzFile);
};
//===================================================================
//
// Program Main
//
//===================================================================
int main(int argc, char* argv[])
{
Engine* engine = new Engine();
engine->LoadHistory();
engine->CalcMetrics();
engine->CalcFeatures();
engine->SaveFeatures();
engine->ProcessTest("qualifying.txt");
printf("\nDone\n");
getchar();
return 0;
}
//===================================================================
//
// Engine Class
//
//===================================================================
//-------------------------------------------------------------------
// Initialization
//-------------------------------------------------------------------
Engine::Engine(void)
{
m_nRatingCount = 0;
for (int f=0; f<MAX_FEATURES; f++)
{
for (int i=0; i<MAX_MOVIES; i++) m_aMovieFeatures[f][i] = (float)INIT;
for (int i=0; i<MAX_CUSTOMERS; i++) m_aCustFeatures[f][i] = (float)INIT;
}
m_nCustomers = 0;
for (int f=0; f<HASH_SIZE; f++) {
m_aCustomerHash[f] = (Hash*)malloc( 10 * sizeof(Hash) );
m_nCustomerHashPos[f] = 0;
m_nCustomerHashSize[f] = 10;
}
}
//-------------------------------------------------------------------
// Calculations - This section contains all of the relevant code
//-------------------------------------------------------------------
//
// CalcMetrics
// - Loop through the history and pre-calculate metrics used in the training
// - Also re-number the customer id's to fit in a fixed array
//
void Engine::CalcMetrics()
{
int i, cid, k, index;
Hash* htemp;
/* IdItr itr; */
printf("\nCalculating intermediate metrics\n\n");
// Process each row in the training set
for (i=0; i<m_nRatingCount; i++)
{
if ((i % 1000000)==0) printf("."), fflush(stdout);
Data* rating = m_aRatings + i;
// Increment movie stats
m_aMovies[rating->MovieId].RatingCount++;
m_aMovies[rating->MovieId].RatingSum += rating->Rating;
// Add customers (using a map to re-number id's to array indexes)
cid = GetCustomerId( rating->CustId );
if ( cid<0 )
{
/* find pos to insert CustId */
index = GetCustomerHashId(rating->CustId);
if (m_nCustomerHashSize[index] <= m_nCustomerHashPos[index]) {
m_nCustomerHashSize[index] += 10;
htemp = (Hash*)malloc( m_nCustomerHashSize[index] * sizeof(Hash) );
for(k=0;k<m_nCustomerHashPos[index];k++) {
htemp[k].CustId = m_aCustomerHash[index][k].CustId;
htemp[k].RunningId = m_aCustomerHash[index][k].RunningId;
}
free(m_aCustomerHash[index]);
m_aCustomerHash[index] = htemp;
}
cid = m_nCustomers++;
m_aCustomerHash[index][m_nCustomerHashPos[index]].CustId = rating->CustId;
m_aCustomerHash[index][m_nCustomerHashPos[index]].RunningId = cid;
m_nCustomerHashPos[index]++;
if (m_nCustomers > MAX_CUSTOMERS) {
printf("too many customers!\n");
return;
}
// Store off old sparse id for later
m_aCustomers[cid].CustomerId = rating->CustId;
// Init vars to zero
m_aCustomers[cid].RatingCount = 0;
m_aCustomers[cid].RatingSum = 0;
}
// Swap sparse id for compact one
rating->CustId = cid;
m_aCustomers[cid].RatingCount++;
m_aCustomers[cid].RatingSum += rating->Rating;
}
// Do a follow-up loop to calc movie averages
for (i=0; i<MAX_MOVIES; i++)
{
Movie* movie = m_aMovies+i;
movie->RatingAvg = movie->RatingSum / (1.0 * movie->RatingCount);
movie->PseudoAvg = (3.23 * 25 + movie->RatingSum) / (25.0 + movie->RatingCount);
}
printf("\n");
}
//
// SaveFeatures
//
void Engine::SaveFeatures()
{
FILE *f;
int i,j;
f = fopen(FEATURE_FILE,"w");
fprintf(f,"Featurefile:Version1.0\n");
for(i=0;i<MAX_FEATURES;i++) {
fprintf(f,"\nMOVIE[%d]\n",i);
for(j=0;j<MAX_MOVIES;j++)
fprintf(f," %g",m_aMovieFeatures[i][j]);
fprintf(f,"\nCUSTOMER[%d]\n",i);
for(j=0;j<MAX_CUSTOMERS;j++)
fprintf(f," %g",m_aCustFeatures[i][j]);
}
fprintf(f,"\n");
fclose(f);
}
//
// CalcFeatures
// - Iteratively train each feature on the entire data set
// - Once sufficient progress has been made, move on
//
void Engine::CalcFeatures()
{
int f, e, i, custId, cnt = 0;
Data* rating;
double err, p, sq, rmse_last, rmse = 2.0;
short movieId;
float cf, mf;
for (f=0; f<MAX_FEATURES; f++)
{
printf("\n--- Calculating feature: %d ---\n", f);
// Keep looping until you have passed a minimum number
// of epochs or have stopped making significant progress
for (e=0; (e < MIN_EPOCHS) || (rmse <= rmse_last - MIN_IMPROVEMENT); e++)
{
cnt++;
sq = 0;
rmse_last = rmse;
for (i=0; i<m_nRatingCount; i++)
{
rating = m_aRatings + i;
movieId = rating->MovieId;
custId = rating->CustId;
// Predict rating and calc error
p = PredictRating(movieId, custId, f, rating->Cache, true);
err = (1.0 * rating->Rating - p);
sq += err*err;
// Cache off old feature values
cf = m_aCustFeatures[f][custId];
mf = m_aMovieFeatures[f][movieId];
// Cross-train the features
m_aCustFeatures[f][custId] += (float)(LRATE * (err * mf - K * cf));
m_aMovieFeatures[f][movieId] += (float)(LRATE * (err * cf - K * mf));
}
rmse = sqrt(sq/m_nRatingCount);
printf(" <set x='%d' y='%f' />\n",cnt,rmse);
}
// Cache off old predictions
for (i=0; i<m_nRatingCount; i++)
{
rating = m_aRatings + i;
rating->Cache = (float)PredictRating(rating->MovieId, rating->CustId, f, rating->Cache, false);
}
}
}
//
// PredictRating
// - During training there is no need to loop through all of the features
// - Use a cache for the leading features and do a quick calculation for the trailing
// - The trailing can be optionally removed when calculating a new cache value
//
double Engine::PredictRating(short movieId, int custId, int feature, float cache, bool bTrailing)
{
// Get cached value for old features or default to an average
double sum = (cache > 0) ? cache : 1; //m_aMovies[movieId].PseudoAvg;
// Add contribution of current feature
sum += m_aMovieFeatures[feature][movieId] * m_aCustFeatures[feature][custId];
if (sum > 5) sum = 5;
if (sum < 1) sum = 1;
// Add up trailing defaults values
if (bTrailing)
{
sum += (MAX_FEATURES-feature-1) * (INIT * INIT);
if (sum > 5) sum = 5;
if (sum < 1) sum = 1;
}
return sum;
}
//
// PredictRating
// - This version is used for calculating the final results
// - It loops through the entire list of finished features
//
double Engine::PredictRating(short movieId, int custId)
{
double sum = 1; //m_aMovies[movieId].PseudoAvg;
for (int f=0; f<MAX_FEATURES; f++)
{
sum += m_aMovieFeatures[f][movieId] * m_aCustFeatures[f][custId];
if (sum > 5) sum = 5;
if (sum < 1) sum = 1;
}
return sum;
}
//-------------------------------------------------------------------
// Data Loading / Saving
//-------------------------------------------------------------------
//
// LoadHistory
// - Loop through all of the files in the training directory
//
void Engine::LoadHistory()
{
FILE *lfile;
bool bContinue = true;
int read,count = 0; // TEST
char buf[50];
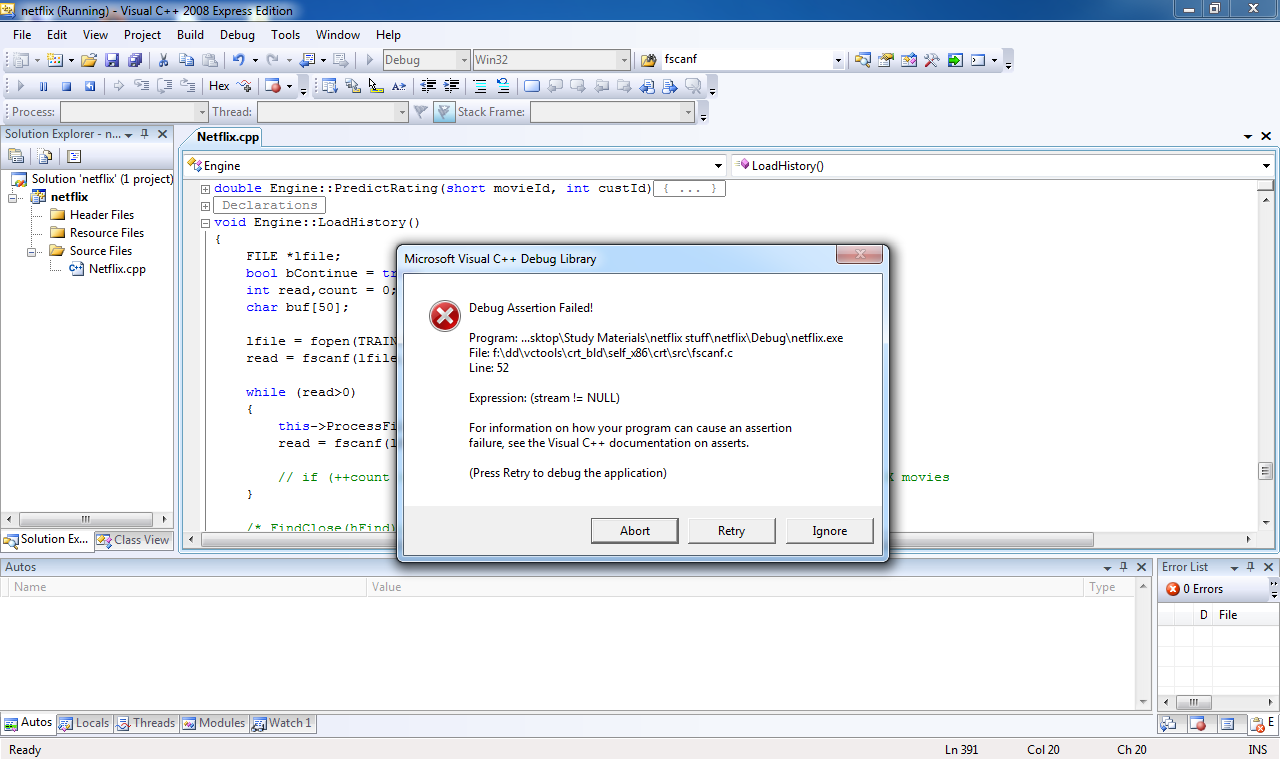
lfile = fopen(TRAINING_LIST,"r");
read = fscanf(lfile,"%s\n",&buf);
while (read>0)
{
this->ProcessFile(buf);
read = fscanf(lfile,"%s\n",&buf);
// if (++count > 999) break; // TEST: Uncomment to only test with the first X movies
}
/* FindClose(hFind); */
fclose(lfile);
}
//
// ProcessFile
// - Load a history file in the format:
//
// <MovieId>:
// <CustomerId>,<Rating>
// <CustomerId>,<Rating>
// ...
void Engine::ProcessFile(char* pwzFile)
{
FILE *stream;
char pwzBuffer[1000];
sprintf(pwzBuffer,TRAINING_FILE,pwzFile);
int custId, movieId, rating, pos = 0;
int read;
printf("Processing file: %s\n", pwzBuffer);
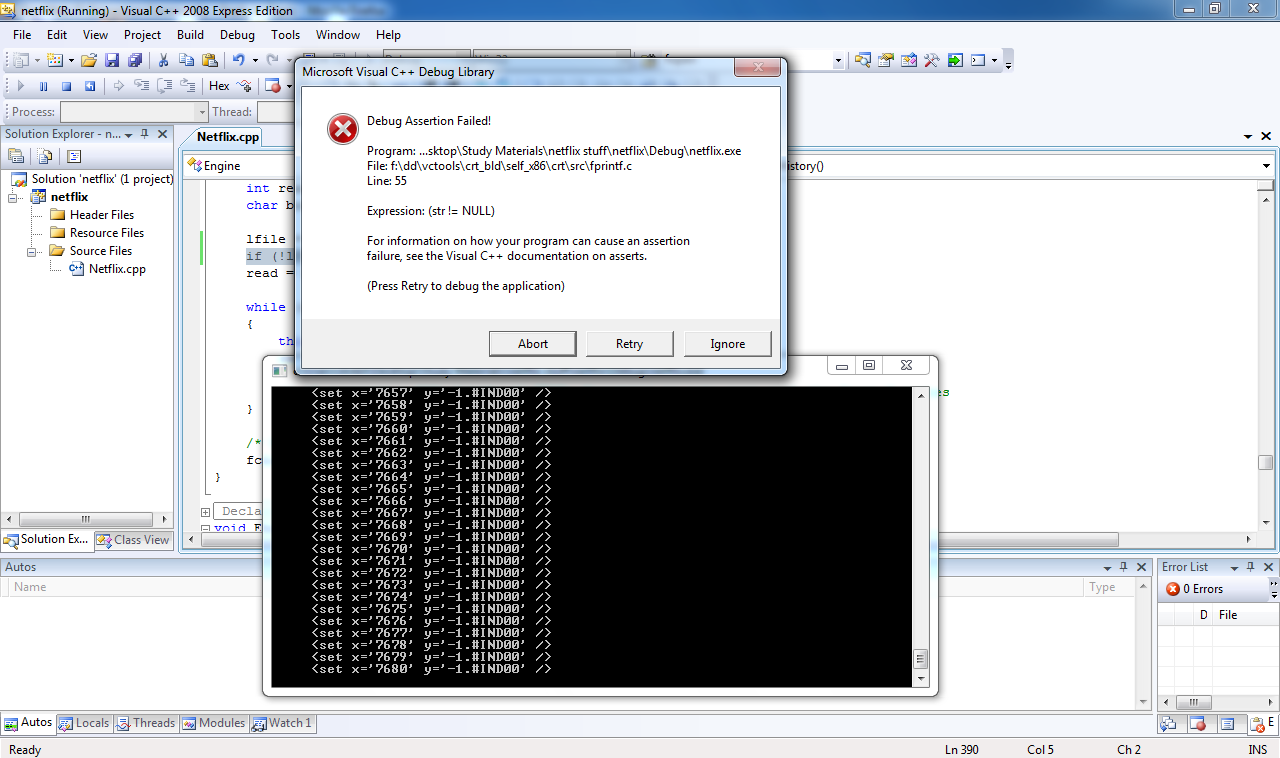
stream = fopen(pwzBuffer, "r");
if (!stream) return;
// First line is the movie id
fscanf(stream,"%s\n",&pwzBuffer);
ParseInt(pwzBuffer, (int)strlen(pwzBuffer), pos, movieId);
m_aMovies[movieId].RatingCount = 0;
m_aMovies[movieId].RatingSum = 0;
// Get all remaining rows
read = fscanf(stream,"%s\n",&pwzBuffer);
while ( read>0 )
{
pos = 0;
ParseInt(pwzBuffer, (int)strlen(pwzBuffer), pos, custId);
ParseInt(pwzBuffer, (int)strlen(pwzBuffer), pos, rating);
m_aRatings[m_nRatingCount].MovieId = (short)movieId;
m_aRatings[m_nRatingCount].CustId = custId;
m_aRatings[m_nRatingCount].Rating = (BYTE)rating;
m_aRatings[m_nRatingCount].Cache = 0;
m_nRatingCount++;
read = fscanf(stream,"%s\n",&pwzBuffer);
}
// Cleanup
fclose( stream );
}
//
// ProcessTest
// - Load a sample set in the following format
//
// <Movie1Id>:
// <CustomerId>
// <CustomerId>
// ...
// <Movie2Id>:
// <CustomerId>
//
// - And write results:
//
// <Movie1Id>:
// <Rating>
// <Raing>
// ...
void Engine::ProcessTest(char* pwzFile)
{
FILE *streamIn, *streamOut;
char pwzBuffer[1000];
int custId, movieId, pos = 0;
double rating;
bool bMovieRow;
int read;
sprintf(pwzBuffer, TEST_PATH, pwzFile);
printf("\n\nProcessing test: %s\n", pwzBuffer);
streamIn = fopen(pwzBuffer, "r");
if (!streamIn) return;
streamOut = fopen(PREDICTION_FILE, "w");
if (!streamOut) return;
read = fscanf(streamIn,"%s\n",&pwzBuffer);
while ( read>0 )
{
bMovieRow = false;
for (int i=0; i<(int)strlen(pwzBuffer); i++)
{
bMovieRow |= (pwzBuffer[i] == 58);
}
pos = 0;
if (bMovieRow)
{
ParseInt(pwzBuffer, (int)strlen(pwzBuffer), pos, movieId);
// Write same row to results
fprintf(streamOut,"%s\n",&pwzBuffer);
}
else
{
ParseInt(pwzBuffer, (int)strlen(pwzBuffer), pos, custId);
custId = GetCustomerId(custId);
rating = PredictRating(movieId, custId);
// Write predicted value
sprintf(pwzBuffer,"%5.3f\n",rating);
fprintf(streamOut,"%s",&pwzBuffer);
}
//wprintf(L"Got Line: %d %d %d \n", movieId, custId, rating);
read = fscanf(streamIn,"%s\n",&pwzBuffer);
}
// Cleanup
fclose( streamIn );
fclose( streamOut );
}
//-------------------------------------------------------------------
// Helper Functions
//-------------------------------------------------------------------
bool Engine::ReadNumber(char* pwzBufferIn, int nLength, int &nPosition, char* pwzBufferOut)
{
int count = 0;
int start = nPosition;
char wc = 0;
// Find start of number
while (start < nLength)
{
wc = pwzBufferIn[start];
if ((wc >= 48 && wc <= 57) || (wc == 45)) break;
start++;
}
// Copy each character into the output buffer
nPosition = start;
while (nPosition < nLength && ((wc >= 48 && wc <= 57) || wc == 69 || wc == 101 || wc == 45 || wc == 46))
{
pwzBufferOut[count++] = wc;
wc = pwzBufferIn[++nPosition];
}
// Null terminate and return
pwzBufferOut[count] = 0;
return (count > 0);
}
bool Engine::ParseFloat(char* pwzBuffer, int nLength, int &nPosition, float& fValue)
{
char pwzNumber[20];
bool bResult = ReadNumber(pwzBuffer, nLength, nPosition, pwzNumber);
fValue = (bResult) ? (float)atof(pwzNumber) : 0;
return false;
}
bool Engine::ParseInt(char* pwzBuffer, int nLength, int &nPosition, int& nValue)
{
char pwzNumber[20];
bool bResult = ReadNumber(pwzBuffer, nLength, nPosition, pwzNumber);
nValue = (bResult) ? atoi(pwzNumber) : 0;
return bResult;
}
int Engine::GetCustomerHashId( int CustId )
{
return CustId % HASH_SIZE;
}
int Engine::GetCustomerId(int CustId)
{
static int i,index;
index = GetCustomerHashId( CustId );
for(i=0;i<m_nCustomerHashPos[index];i++)
if (m_aCustomerHash[index][i].CustId == CustId) return m_aCustomerHash[index][i].RunningId;
return -1;
}i am using visual C++ express edition to run this code....it compiles without any error but when i debug it, it gives me the following msg...there is a screen shot of tht msg...pls suggest me some ways to solve it and help me debug it