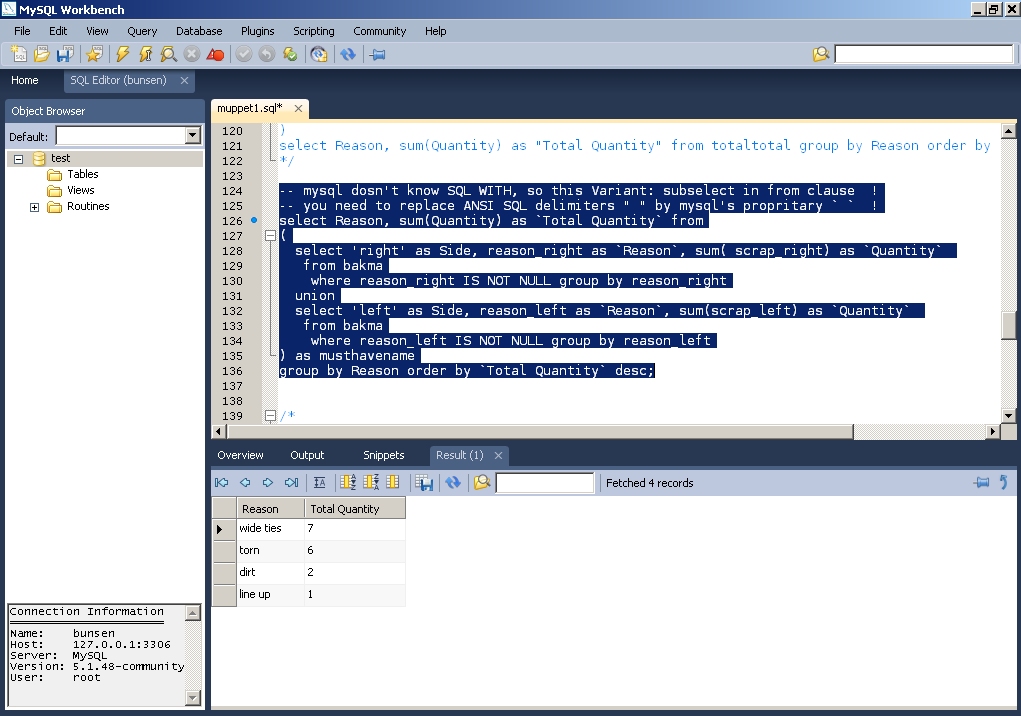
Hi muppet
CASE is kind of function which is only allowed to return a constant value. However with "'07:20:00' and '15:19:59'" you return part of an executeable sql statement (AND) what is illegal. Actually, mysql must notify an error yet remains silently.
Also experts then rubbing their eyes in disbelief for their statement is considered to be correct by the mighty system though the result is absurd ("...note the time in the timestamp is outside of where it should be.")
However that be, you could try this modified query:
select day(timestamp) as tamp, tech, packer_l, packer_r, (packed_l + packed_r) as packed, timestamp as ts
FROM abm_status
where
(
case
when (time(timestamp) between '07:20:00' and '15:19:59') then 'day'
when (time(timestamp) between '15:20:00' and '23:19:59') then 'swing'
else 'night'
end
=
case
when (time(now()) between '07:20:00' and '15:19:59') then 'day'
when (time(now()) between '15:20:00' and '23:19:59') then 'swing'
else 'night'
end
)
and tech != ''
and tech != 'Dummy Login'
and YEAR(timestamp) = YEAR(CURDATE()) AND MONTH(timestamp) = MONTH(CURDATE())
order by packed desc; /* limit 1 ;*/Please tell me whether this will work successfully, also what modifications you did to get it going.
Hint: You can't write that: "(time(now()) between '23:20:00' and '07:19:59')". Also this is formally incorrect for the left boundary must always be less or equal to the right one, usually you don't get an error reported, even on Oacle database. Neither you can interchange the boundaries. Instead you should write:
(time(now()) between …