In my recent journey of developing various AI solutions powered by Language Models (LLMs), a significant question has emerged: Should we harness the capabilities of Retrieval Augmented Generation (RAG), or should we opt for the path of custom fine-tuning? This decision can profoundly impact the performance and adaptability of our AI systems. Let's delve into the considerations that can guide you in making this pivotal choice.
1. Access to External Data
Fine-Tuning: Relying on Existing Knowledge
Fine-tuning predominantly relies on existing knowledge within the model. It's ideal when your AI system can operate effectively with the data it has been initially trained on. However, it's worth noting that for fine-tuning to incorporate external data effectively, you would need a constantly updated dataset, which can be challenging to maintain, especially for rapidly changing information.
RAG: The Power of External Knowledge
One of the standout advantages of RAG lies in its ability to seamlessly tap into external sources like databases and documents. It's akin to giving your LLM the ability to 'look up' relevant information, enriching its responses with real-world data. When your application demands real-time access to external information, RAG is the go-to choice.
2. Modifying Model Behavior and Knowledge
Fine-Tuning: Tailoring to Your Domain
If you aim to infuse your AI with specific linguistic styles or industry-specific jargon, fine-tuning is your best ally. It allows you to mold the LLM to match your domain's unique tone and expertise. Fine-tuning lets you achieve a high degree of precision in tailoring the model's output to your exact requirements.
RAG: Prioritizing Relevance
On the flip side, RAG excels at retrieving information from external sources and prioritizing relevance. However, it may not always capture the specialized nuances or linguistic idiosyncrasies you desire. It's more about delivering contextually relevant information.
3. Availability of Training Data
Fine-Tuning: Data-Hungry Approach
Fine-tuning thrives on high-quality, domain-specific datasets. To achieve significant improvements in model performance, you'll need ample data with rich details and nuances. If your dataset is limited, fine-tuning might not yield the desired results.
RAG: Less Dependent on Domain-Specific Data
RAG is more forgiving when it comes to the quantity of domain-specific training data. Its real strength lies in its ability to fetch insights from external sources, making it a valuable choice even with limited data.
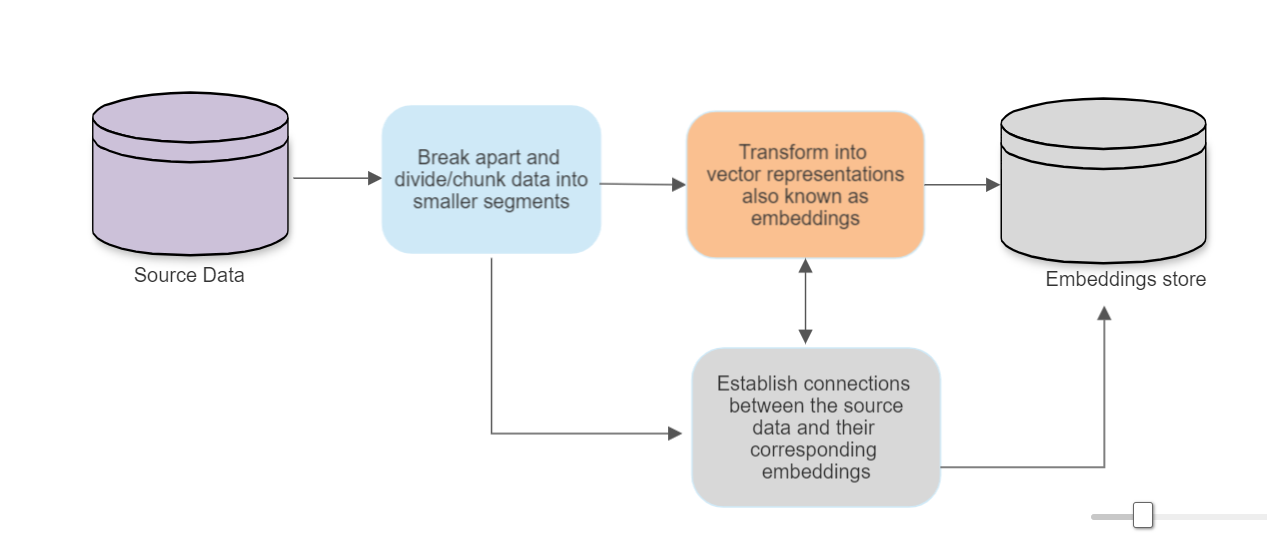
4. Handling Hallucinations
Fine-Tuning: Addressing Fabrications
While fine-tuning can be directed to reduce such fabrications, it's not a guaranteed solution. It might require additional training and data filtering to minimize these inaccuracies effectively.
RAG: Fact-Driven Reliability
Language models can sometimes generate information that isn't entirely factual, often referred to as "hallucinations." RAG systems, with their retrieval-before-response design, are less prone to this issue. They rely on external data, making them a reliable choice for fact-driven applications where accuracy is paramount.
6. Transparency Needs
Fine-Tuning: The Black Box Conundrum
Fine-tuning often operates like a black box, where it's not always clear why the model responds the way it does. This lack of transparency can be a drawback in scenarios where accountability and understanding the decision-making process are crucial.
RAG: Tracing Answers to Sources
Conversely, RAG offers a higher level of transparency and accountability. You can often trace back the model's answers to specific data sources, providing a more transparent view of how the AI arrives at its conclusions.
7. Data Dynamics
Fine-Tuning: Static Snapshot
If your data environment is dynamic and subject to frequent changes, fine-tuning can be challenging to maintain. The fine-tuned model becomes a snapshot of a specific point in time, and keeping it updated with the evolving data can be resource-intensive.
RAG: Real-Time Data Access
RAG, with its real-time data retrieval mechanism, remains updated in sync with the ever-changing data landscape. This makes it an excellent choice for applications operating in dynamic data environments.
In conclusion, the choice between RAG and fine-tuning ultimately depends on the specific needs of your application. Each approach has its unique strengths, and aligning them with your goals and data availability will determine the best fit for enhancing your Language Model. Whether you're seeking real-time external knowledge or customizing linguistic styles, making an informed choice is key to maximizing the potential of your AI solution.
