In one of my previous articles, you saw a comparison of GPT-4o vs. Claude 3.5 sonnet for zero-shot text classification. In that article; we performed multi-class text classification where input tweets belonged to one of the three categories.
In this article, we will go a step further and perform zero-shot multi-label text classification with GPT-4o and Claude 3.5 sonnet models. We will compare the two models using accuracy and hamming loss criteria and see which model is suited for zero-shot multi-label text classification.
So, let's begin without ado.
Installing and Importing Required Libraries
We will call the Claude 3.5 sonnet and GPT-4o models using the Anthropic and OpenAI Python libraries.
The following script installs these libraries.
!pip install anthropic
!pip install openai
The script below imports the required libraries into your Python application.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from itertools import combinations
from collections import Counter
from sklearn.metrics import hamming_loss, accuracy_score
import anthropic
from openai import OpenAI
from google.colab import userdata
OPENAI_API_KEY = userdata.get('OPENAI_API_KEY')
ANTHROPIC_API_KEY = userdata.get('ANTHROPIC_API_KEY')
Importing and Visualizing the Dataset
We will use a multi-label text classification dataset from Kaggle containing research paper titles and abstracts that can belong to one or more of the six output categories: Computer Science, Physics, Mathematics, Statistics, Quantitative Biology, and Quantitative Finance.
The following script imports the training set from the dataset and plots the dataset header.
## dataset download link
## https://www.kaggle.com/datasets/shivanandmn/multilabel-classification-dataset?select=train.csv
dataset = pd.read_csv("/content/train.csv")
print(f"Dataset Shape: {dataset.shape}")
dataset.head()
Output:

The dataset consists of 9 columns. The ID column contains the paper ID. The TITLE and ABSTRACT columns contain research papers' titles and abstracts, respectively. In the rest of the columns, a one signifies that the paper belongs to this category. A zero means that the paper does not belong to this category.
Let's filter papers that belong to at least two categories since we want to perform multi-label classification.
subjects = ["Computer Science", "Physics", "Mathematics", "Statistics", "Quantitative Biology", "Quantitative Finance"]
filtered_dataset = dataset[(dataset[subjects] == 1).sum(axis=1) >= 2]
print(f"Filtered Dataset Shape: {filtered_dataset.shape}")
filtered_dataset.head()Output:

Next, we will plot a heatmap that shows the co-occurrences of research papers in various categories.
filtered_dataset[subjects] = filtered_dataset[subjects].astype(int)
pair_counts = {pair: 0 for pair in combinations(subjects, 2)}
# Count occurrences where both subjects in each pair have a value of 1
for subject1, subject2 in pair_counts:
pair_counts[(subject1, subject2)] = ((filtered_dataset[subject1] == 1) & (filtered_dataset[subject2] == 1)).sum()
# Convert the pair counts to a DataFrame suitable for a heatmap
pair_counts_df = pd.DataFrame(0, index=subjects, columns=subjects)
for (subject1, subject2), count in pair_counts.items():
pair_counts_df.loc[subject1, subject2] = count
pair_counts_df.loc[subject2, subject1] = count # Ensure symmetry
# Plotting the heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(pair_counts_df,
annot=True,
fmt="d",
cmap="Blues",
square=True,
cbar=True)
plt.title("Pairing Count of Columns with Both Values as 1")
plt.show()
Output:
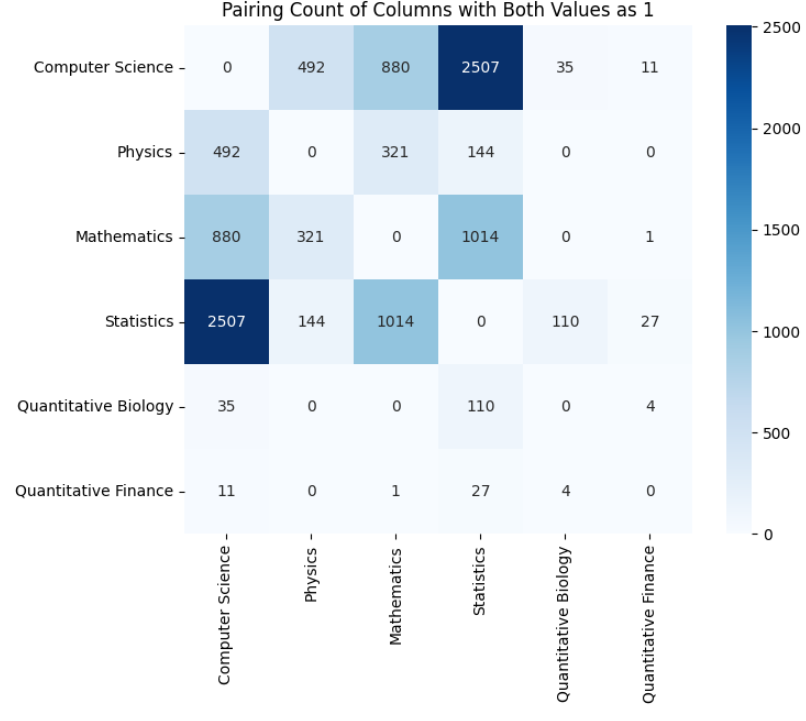
The above output shows that most research papers in the dataset are grouped in the Computer Science—Statistics and Mathematics—Statistics categories.
In the next section, we will use the Claude 3.5 Sonnet and GPT-4o models to classify the research papers in the dataset using multi-label classification.
Zero-Shot Multi-label Text Classification
We will define the find_research_category() method that takes as parameters the Anthropic or OpenAI API client, the model name from the API, and the dataset.
Inside the method, we iterate through all the rows and extract the paper titles and abstracts. Next, we will write a prompt that tells the models that using the research paper title and abstract, they have to classify the paper into two or more of the predefined subject categories.
Next, depending on the model type, we send the prompt to Anthropic or OpenAI and retrieve the comma-separated list of subject types for the research paper.
def find_research_category(client, model, dataset):
outputs = []
i = 0
for _, row in sampled_df.iterrows():
title = row['TITLE']
abstract = row['ABSTRACT']
content = """You are an expert in various scientific domains.
Given the following research paper title and abstract, classify the research paper into at least two or more of the following categories:
- Computer Science
- Physics
- Mathematics
- Statistics
- Quantitative Biology
- Quantitative Finance
Return only a comma-separated list of the categories (e.g., [Computer Science,Physics] or [Computer Science,Physics,Mathematics]).
Use the exact case sensitivity and spelling of the categories provided above.
text: Title: {}\nAbstract: {}""".format(title, abstract)
research_category = ""
if model == "gpt-4o":
research_category = client.chat.completions.create(
model= model,
temperature = 0,
max_tokens = 100,
messages=[
{"role": "user", "content": content}
]
).choices[0].message.content
if model == "claude-3-5-sonnet-20241022":
research_category = client.messages.create(
model= model,
max_tokens=10,
temperature=0.0,
messages=[
{"role": "user", "content": content}
]
).content[0].text
outputs.append(research_category)
print(i + 1, research_category)
i += 1
return outputs
The response from the find_research_category() method is a list of lists where each internal list contains subject categories. We will convert these subject categories into a Pandas dataframe to compare the model outputs with target labels.
def parse_outputs_to_dataframe(outputs):
subjects = ["Computer Science", "Physics", "Mathematics", "Statistics", "Quantitative Biology", "Quantitative Finance"]
# Remove square brackets and split the subjects for each entry in outputs
parsed_data = [item.strip('[]').split(',') for item in outputs]
# Create an empty DataFrame with columns for each subject, initializing with 0s
df = pd.DataFrame(0, index=range(len(parsed_data)), columns=subjects)
# Populate the DataFrame with 1s based on the presence of each subject in each row
for i, subjects_list in enumerate(parsed_data):
for subject in subjects_list:
if subject in subjects:
df.loc[i, subject] = 1
return df
We will randomly select the first 100 records from the dataset and use these records to make predictions. You can select more records. However, it can cost more since the OpenAI and Claude APIs are not free.
sampled_df = filtered_dataset.sample(n=100, random_state=42)Multi-label Text Classification with GPT-4o
Let's first do multi-label classification with GPT-4o. To do so, we will create an OpenAI client object and pass it the OpenAI API key.
We will pass the client object and the gpt-4o model ID to the find_research_category() method, which returns model predictions.
client = OpenAI(api_key = OPENAI_API_KEY,)
model = "gpt-4o"
outputs = find_research_category(client, model, sampled_df)
Output:
We will convert model predictions into Pandas dataframe using the parse_outputs_to_dataframe() method.
Finally, we calculate the hamming loss and model accuracy using the hamming_loss and accuracy_score functions from the sklearn library.
predictions = parse_outputs_to_dataframe(outputs)
targets = sampled_df[subjects]
# Calculate Hamming Loss
hamming = hamming_loss(targets, predictions)
print(f"Hamming Loss: {hamming}")
# Calculate Subset Accuracy (Exact Match Ratio)
subset_accuracy = accuracy_score(targets, predictions)
print(f"Subset Accuracy: {subset_accuracy}")
Output:
Hamming Loss: 0.16
Subset Accuracy: 0.4
We achieved a hamming loss of 0.16, which shows that 16% of labels for each record were incorrectly predicted. The lower the hamming loss, the better the model performs.
Similarly, we achieved an accuracy of 40%, which means that the model correctly predicted all the categories in 40% of the records.
Multi-label Text Classification with Claude 3.5 Sonnet
Next, we will make predictions with the Claude 3.5 sonnet. We will create an object of the Anthropic class and pass it the Anthropic API key.
To retrieve model responses, we pass the Anthropic client and the Claude 3.5 sonnet model ID to the find_research_category() method.
client = anthropic.Anthropic(api_key = ANTHROPIC_API_KEY)
model = "claude-3-5-sonnet-20241022"
outputs = find_research_category(client, model, sampled_df)Output:

Next, we parse the model outputs to a dataframe using the parse_outputs_to_dataframe() method and print the hamming loss and model accuracy for the Claude 3.5 sonnet model.
predictions = parse_outputs_to_dataframe(outputs)
targets = sampled_df[subjects]
# Calculate Hamming Loss
hamming = hamming_loss(targets, predictions)
print(f"Hamming Loss: {hamming}")
# Calculate Subset Accuracy (Exact Match Ratio)
subset_accuracy = accuracy_score(targets, predictions)
print(f"Subset Accuracy: {subset_accuracy}")
Output:
Hamming Loss: 0.17166666666666666
Subset Accuracy: 0.29
The output shows that the Claude 3.5 sonnet model performs slightly better than GPT-4o regarding hamming loss, which means that the Claude model predicted fewer labels incorrectly. However, Claude returned an accuracy of 29% for an exact label match, significantly less than GPT-4o.
Conclusion
Claude 3.5 sonnet and OpenAI GPT-4o models achieve brilliant zero-shot multi-label text classification results. In this article, you saw how to use these models for multi-label text classification and convert the model predictions into Pandas dataframe to evaluate model performance.
The results show that while Claude 3.5 makes fewer mistakes for predicted individual labels, the GPT-4o is significantly better if you look for an exact multi-label match for your input text.