Have two CSV files containing client records and need to compare the two and then output to a third file those rows where there are differences to the values within the record (row) as well as output those records (rows) on the second file that are not on first file .
Example: File 1:
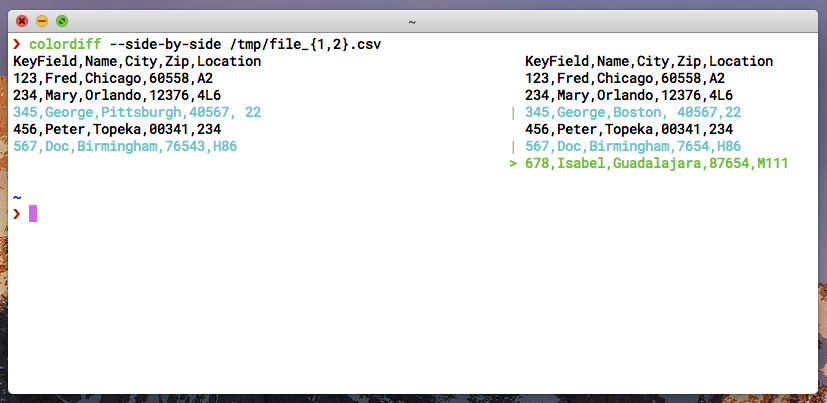
KeyField,Name,City, Zip,Location
123,Fred,Chicago,60558,A2
234,Mary,Orlando,12376,4L6
345,George,Pittsburgh,40567, 22
456,Peter,Topeka,00341,234
567,Doc,Birmingham,76543,H86
File 2:
KeyField,Name,City,Zip,Location
123,Fred,Chicago,60558,A2
234,Mary,Orlando,12376,4L6
345,George,Boston, 40567,22
456,Peter,Topeka,00341,234
567,Doc,Birmingham,7654,H86
678,Isabel,Guadalajara,87654,M111
The results should create a file containing :
345,George,Boston,40567,22
678,Isabel,Guadalajara,87654,M111
The following code gets me in the neighborhood as a visual check:
import os
import difflib
f=open('original.csv','r') #open a file
f1=open('new.csv','r') #open another file to compare
str1=f.read()
str2=f1.read()
str1=str1.split() #split the words in file by default through the spce
str2=str2.split()
d=difflib.Differ() # compare and just print
diff=list(d.compare(str1,str2))
print '\n'.join(diff)Can somebody suggest a quick solution, please?