Hi,
i have a textfile with a string in it. The string is built like this:
test ="""
[
"this is a text and its supposed to contain every possible char."
],
[
"like *.;#]§< and many more."
],
[
"plus there are even
newlines
in it."
]"""I want to parse out each text in between the square brackets and the quotes. So my desired output would be a list like the following:
['this is a text and its supposed to contain every possible char.', 'like *.;#]§< and many more.', 'plus there are even newlines in it.']
I tried the following regex with the corresping output:
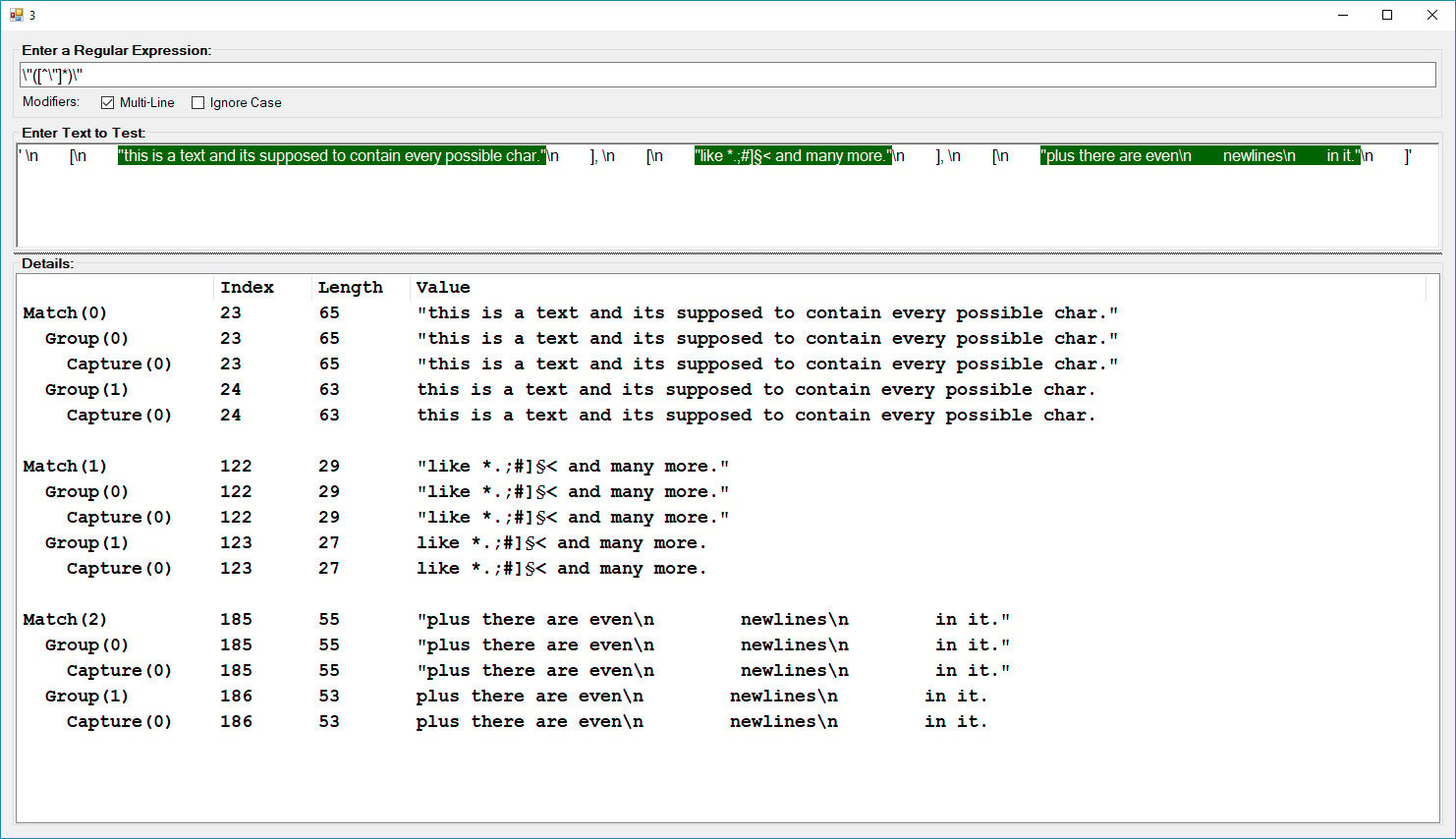
my_list = re.findall(r'(?<=\[\n {8}\").*(?=\"\n {8}\])', test)
print (my_list)
['this is a text and its supposed to contain every possible char.', 'like *.;#]§< and many more.']So this one is close to what i want. A list of two elements containing only the text between the square brackets and the quotes. But it doesnt include the third element because there are newlines in it, which are not covered by '.'.
So i tried another regex:
my_list = re.findall(r'(?<=\[\n {8}\")[\s\S]*(?=\"\n {8}\])', test)
print (my_list)
['this is a text and its supposed to contain every possible char."\n ], \n [\n "like *.;#]§< and many more."\n ], \n [\n "plus there are even\n newlines\n \n in it.']This time it includes the third element but it seems it doesnt take the look ahead into account at all and doesnt split the text since the list contains of only one element.
How can i get the desired output with regex?
Or is there even a faster or more clear way to get it without regex (beautifulsoup maybe?)?
I am thankful for any help and hints. Thank you in advance.