In the last article, I explained how you can use the DeepSeek-R1-Distill-Qwen-32B model for text classification and summarization problems.
In this article, we will use the DeepSeek-R1-Distill-Llama-70b for the same tasks.
Following results from the DeepSeek-AI's official paper show that DeepSeek-R1-Distill-Llama-70b outperform the other distilled models on 4 out of 6 benchmarks.
Output:
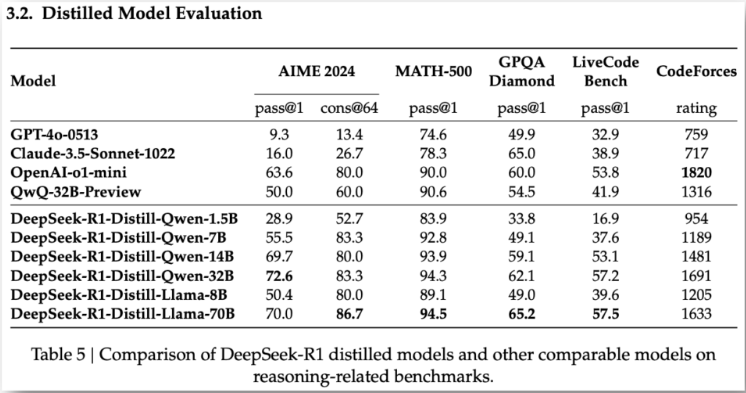
So, let's begin without ado and see what results we achieve with DeepSeek-R1-Distill-Llama-70b model.
Importing and Installing Required Libraries
We will access the DeepSeek-R1-Distill-Llama-70b model via the Groq API. To run scripts in this article, you will need the Groq API Key.
The following script installs the Python Groq library and other Python modules you will need to run scripts for in this article.
!pip install groq
!pip install rouge-score
!pip install --upgrade openpyxl
!pip install pandas openpyxlThe script below imports the required libraries.
The following script
from groq import Groq
import os
import pandas as pd
from rouge_score import rouge_scorer
from sklearn.metrics import accuracy_score
from collections import defaultdict
from google.colab import userdataCalling DeepSeek R1 Distill Llama 70B using the Groq API
Let's first see how to call the DeepSeek-R1-Distill-Llama-70b via the Groq API.
First, you will need to create an object of the Groq client and pass it your Groq API key.
Next, we define the generate_response() function, which accepts the system instructions and the user prompt.
Finally, you need to call the chat.completions.create() function of the Groq client object to generate a response via any of the Groq models.
The model ID must be passed to the model attribute of the create() function.
The response from the DeepSeek-R1-Distill-Llama-70b model also contains the reasoning process within the <think> </think> tags. We split the response using the last </think> tag and return the remaining answer to the calling function.
The following script shows an example of calling the DeepSeek-R1-Distill-Llama-70b model using the Groq API.
client = Groq(
api_key=userdata.get('GROQ_API_KEY'),
)
def generate_response(system_instructions, user_query):
response = client.chat.completions.create(
model="deepseek-r1-distill-llama-70b",
temperature = 0,
max_tokens = 1000,
messages=[
{"role": "system", "content": system_instructions},
{"role": "user", "content": user_query}
]
)
output = response.choices[0].message.content
final_response = output.strip().split("</think>")[-1].strip()
return final_response
system_instructions = "You are an expert Pizza chef"
user_query = """Explain the process of baking a pizza in three simple steps."""
response= generate_response(system_instructions, user_query)
print(response)
Output:

Let's now see how to use DeepSeek-R1-Distill-Llama-70b for text classification and summarization.
DeepSeek R1 Distill Llama 70B For Text Classification
We will classify tweets based on sentiment in the Twitter US Airline Sentiment Dataset. The following script imports the dataset and displays its header.
## Dataset download link
## https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment?select=Tweets.csv
dataset = pd.read_csv(r"/content/Tweets.csv")
dataset.head()Output:
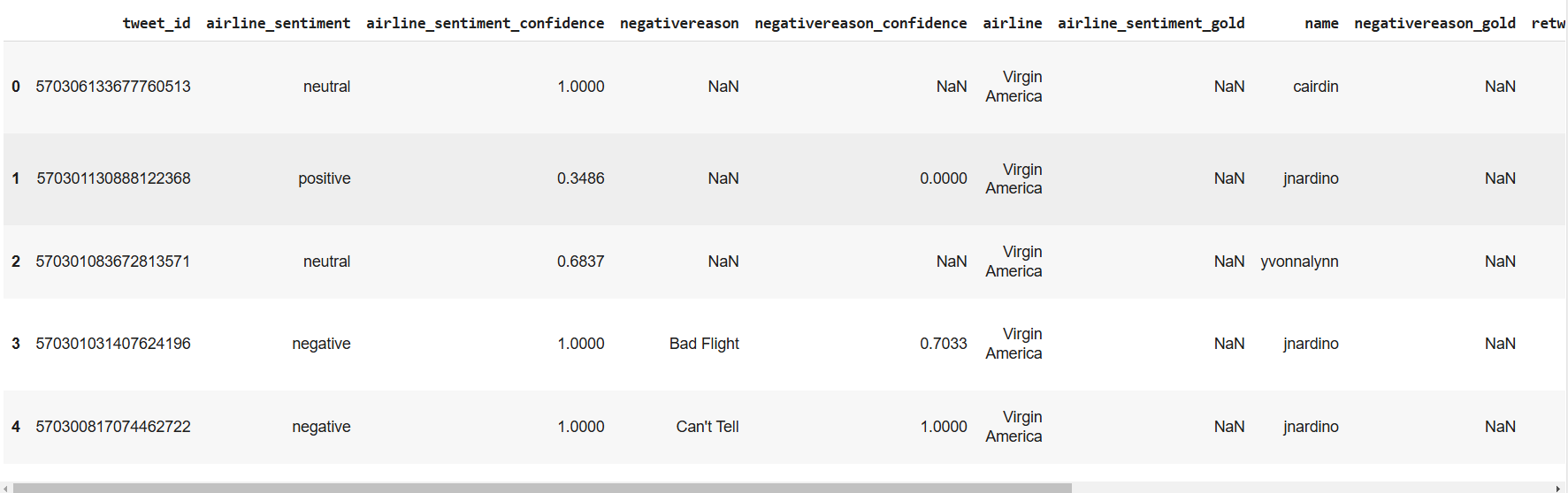
The text column contains the tweet text w,hile the airline_sentiment column contains the corresponding sentiment, which can be positive, negative, or neutral.
We will perform sentiment classification on 100 tweets. The following script creates a dataset of 100 randomly selected tweets, with 34 tweets labeled as neutral, 33 as positive, and 33 as negative.
# Remove rows where 'airline_sentiment' or 'text' are NaN
dataset = dataset.dropna(subset=['airline_sentiment', 'text'])
# Remove rows where 'airline_sentiment' or 'text' are empty strings
dataset = dataset[(dataset['airline_sentiment'].str.strip() != '') & (dataset['text'].str.strip() != '')]
# Filter the DataFrame for each sentiment
neutral_df = dataset[dataset['airline_sentiment'] == 'neutral']
positive_df = dataset[dataset['airline_sentiment'] == 'positive']
negative_df = dataset[dataset['airline_sentiment'] == 'negative']
# Randomly sample records from each sentiment
neutral_sample = neutral_df.sample(n=34)
positive_sample = positive_df.sample(n=33)
negative_sample = negative_df.sample(n=33)
# Concatenate the samples into one DataFrame
dataset = pd.concat([neutral_sample, positive_sample, negative_sample])
# Reset index if needed
dataset.reset_index(drop=True, inplace=True)
# print value counts
print(dataset["airline_sentiment"].value_counts())
Output:
airline_sentiment
neutral 34
positive 33
negative 33
Name: count, dtype: int64
Next, we will iterate through the list of 100 tweets in our dataset and predict each tweet's sentiment using the generate_response() method we defined earlier.
tweets_list = dataset["text"].tolist()
all_sentiments = []
exceptions = 0
for i, tweet in enumerate(tweets_list, 1):
try:
print(f"Processing tweet {i}")
system_instructions = """You are an expert in annotating tweets with positive, negative, and neutral emotions. Think step by step."""
user_query = (
f"What is the sentiment expressed in the following tweet about an airline? "
f"Select sentiment value from positive, negative, or neutral. "
f"Return only the sentiment value in small letters.\n\n"
f"tweet: {tweet}"
)
sentiment_value = response = generate_response(system_instructions, user_query)
all_sentiments.append({
'tweet_id': i,
'sentiment': sentiment_value
})
print(i, sentiment_value)
except Exception as e:
print("===================")
print("Exception occurred with Tweet:", i, "| Error:", e)
exceptions += 1
print("Total exception count:", exceptions)
Output:
Overall Accuracy: 0.69The above output shows that the DeepSeek-R1-Distill-Llama-70b model achieves an accuracy of 69% which is far less compared to the accuracy (87%) achieved by the DeepSeek-R1-Distill-Qwen-32B model in the previous article.
It is safe to assume that the DeepSeek-R1-Distill-Qwen-32B model is a much better choice for text classification, particularly sentiment classification.
Let's see how both models compare for text summarization.
DeepSeek R1 Distill Llama 70B for Text Summarization
We will summarize articles in the News Article Dataset. The following script imports the dataset.
# Kaggle dataset download link
# https://github.com/reddzzz/DataScience_FP/blob/main/dataset.xlsx
dataset = pd.read_excel(r"/content/dataset.xlsx")
dataset = dataset.sample(frac=1)
print(dataset.shape)
dataset.head()Output:
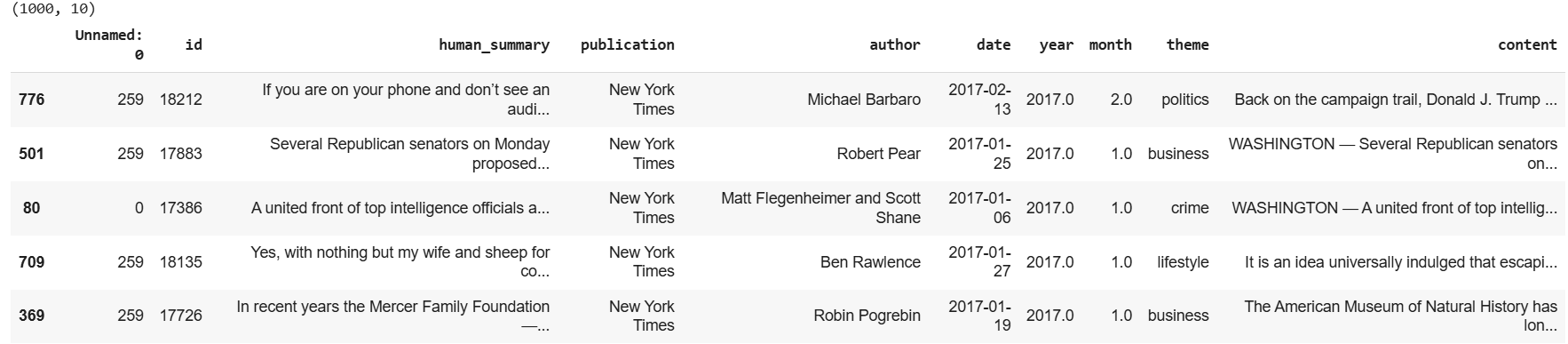
To compare the models, we will use the average ROUGE scores for all model-generated summaries.
The following function returns ROUGE scores for a single summary.
# Function to calculate ROUGE scores
def calculate_rouge(reference, candidate):
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = scorer.score(reference, candidate)
return {key: value.fmeasure for key, value in scores.items()}
Next, we will iterate through the first 20 articles in our dataset, generate article summaries using the generate_response() function, and calculate ROUGE scores for summaries using the calculate_rouge() function.
Finally, we calculate the average ROUGE scores of all the summaries.
Note: We used the first 20 articles to test model performance. You can use any number of articles for testing.
results = []
i = 0
for _, row in dataset[:20].iterrows():
article = row['content']
human_summary = row['human_summary']
i = i + 1
print(f"Summarizing article {i}.")
system_instructions = "You are an expert in creating summaries from text"
user_query = f"""Summarize the following article in 1150 characters. Do not return your thought process. Only the summary.
Your summary will be evaluated using ROUGE score. The summary should look like human created:\n\n{article}\n\nSummary:"""
generated_summary = generate_response(system_instructions, user_query)
rouge_scores = calculate_rouge(human_summary, generated_summary)
results.append({
'article_id': row.id,
'generated_summary': generated_summary,
'rouge1': rouge_scores['rouge1'],
'rouge2': rouge_scores['rouge2'],
'rougeL': rouge_scores['rougeL']
})
# Create a DataFrame with results
results_df = pd.DataFrame(results)
mean_values = results_df[['rouge1', 'rouge2', 'rougeL']].mean()
print(mean_values)
Output:
rouge1 0.347660
rouge2 0.100158
rougeL 0.183272The above output shows ROUGE scores for the DeepSeek-R1-Distill-Llama-70b model. These scores are less than those achieved by the DeepSeek-R1-Distill-Qwen-32B model in the previous article.
Conclusion
This article explains how to summarize text and classify using the DeepSeek-R1-Distill-Llama-70b mode. The results show that for both text classification and summarization tasks, the DeepSeek-R1-Distill-Llama-70b model returns inferior results compared to the much lighter DeepSeek-R1-Distill-Qwen-32B model.
Therefore, we can safely assume that the DeepSeek-R1-Distill-Qwen-32B is the go-to model for text classification and summarization tasks.

