In a previous article, I presented a comparison of DeepSeek-R1-Distill-Llama-70b with the DeepSeek-R1-Distill-Qwen-32B for text classification and summarization.
Both these models are distilled versions of the original DeepSeek R1 model. Recently, I wanted to try the original version of the DeepSeek R1 model using the DeepSeek API. However, I was not able to test it because the DeepSeek API was not allowing requesting the model due to high demand. My other option was to access the model via the Hugging Face API, but I could not run that either since it requires very high memory.
Finally, I found a solution via the FireworksAI API. Fireworks AI provides access to the DeepSeek R1 model hosted inside the United States, so you do not have to worry about sending your data to undesired locations.
In this article, you will see a comparison of the original DeepSeek R1 model with Llama 3.1-405B model for text classification and summarization.
So, let's begin without ado.
Importing and Installing Required Libraries
The following script installs the Fireworks Python library and the other libraries required to run scripts in this article.
!pip install --upgrade fireworks-ai
!pip install rouge-score
!pip install --upgrade openpyxl
!pip install pandas openpyxlThe script below imports the required libraries into your Python application.
You will also need the Fireworks API key to access the Fireworks API via the Python library.
from fireworks.client import Fireworks
import os
import pandas as pd
import time
from rouge_score import rouge_scorer
from sklearn.metrics import accuracy_score
from collections import defaultdict
from google.colab import userdata
FW_API_KEY = userdata.get('FW_API_KEY')Calling LLMs Using FireworksAI API
Let's first see how to call an LLM via the Fireworks API.
You must create a client object of the Fireworks class and pass it your API key.
Next, call the chat.completions.create() method of the client object and pass it the path of the model you want to call and the list of system and user messages.
The script below defines the generate_response() function that accepts the Fireworks model path, the system instructions, and the user query and generates the response.
Reasoning models like DeepSeek return the thinking process and the model's answer in the response. If you are only interested in the response, you can split the response string using the </think> delimiter and return what comes after the response.
client = Fireworks(api_key=FW_API_KEY)
def generate_response(model, system_instructions, user_query):
response = client.chat.completions.create(
model=model,
max_tokens=4000,
temperature=0,
messages=[
{
"role": "system",
"content": system_instructions
},
{
"role": "user",
"content": user_query
}
]
)
output = response.choices[0].message.content
if "</think>" in output:
response = output.strip().split("</think>")[-1].strip()
return response
return response.choices[0].message.content
Let's call the DeepSeek R1 model via the Fireworks API using the generate_response() method we just defined.
model = "accounts/fireworks/models/deepseek-r1"
system_instructions = "You are a helpful assistant."
user_query = "How to build muscles. Reply in three lines."
response = generate_response(model, system_instructions, user_query)
print(response)Output:

The response shows that we successfully called the DeepSeek R1 model.
Next, we will compare the DeepSeek R1 and Llama 3.1-405b models for text classification and summarization.
DeepSeek R1 vs. Llama 3.1-405b for Text Classification
We will predict sentiments of tweets from the Twitter US Airline Sentiment Dataset using the DeepSeek and the Llama models. This is the same dataset we used in the previous article for comparing distilled versions of the DeepSeek R1 model.
The following script imports the dataset into a Pandas DataFrame and displays its header.
## Dataset download link
## https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment?select=Tweets.csv
dataset = pd.read_csv(r"/content/Tweets.csv")
dataset.headOutput:
Next, we will fetch 100 tweets, with 34 having neutral sentiment and the remaining 66 evenly divided between positive and negative sentiments, with 33 tweets each. You can use more tweets to test the DeepSeek model if needed.
# Remove rows where 'airline_sentiment' or 'text' are NaN
dataset = dataset.dropna(subset=['airline_sentiment', 'text'])
# Remove rows where 'airline_sentiment' or 'text' are empty strings
dataset = dataset[(dataset['airline_sentiment'].str.strip() != '') & (dataset['text'].str.strip() != '')]
# Filter the DataFrame for each sentiment
neutral_df = dataset[dataset['airline_sentiment'] == 'neutral']
positive_df = dataset[dataset['airline_sentiment'] == 'positive']
negative_df = dataset[dataset['airline_sentiment'] == 'negative']
# Randomly sample records from each sentiment
neutral_sample = neutral_df.sample(n=34)
positive_sample = positive_df.sample(n=33)
negative_sample = negative_df.sample(n=33)
# Concatenate the samples into one DataFrame
dataset = pd.concat([neutral_sample, positive_sample, negative_sample])
# Reset index if needed
dataset.reset_index(drop=True, inplace=True)
# print value counts
print(dataset["airline_sentiment"].value_counts())
Output:
airline_sentiment
neutral 34
positive 33
negative 33
Name: count, dtype: int64
Finally, we define the predict_sentiment() function, which accepts the model (a tuple containing the model name and Fireworks Path for the model) and the sleep time.
We use the sleep time to add a delay between consecutive requests since the DeepSeek R1 model on Fireworks has a rate limit for API calls per minute.
The predict_sentiment() function returns a list containing predicted sentiments of all 100 tweets in the dataset.
def predict_sentiment(model, sleep_time=0):
tweets_list = dataset["text"].tolist()
all_sentiments = []
exceptions = 0
for i, tweet in enumerate(tweets_list, 1):
model_name, model_client = model
try:
system_instructions = "You are an expert in annotating tweets with positive, negative, and neutral emotions"
user_query = (
f"What is the sentiment expressed in the following tweet about an airline? "
f"Select sentiment value from positive, negative, or neutral. "
f"Return only the sentiment value (positive, negative, or neutral) in small letters.\n\n"
f"tweet: {tweet}"
)
sentiment_value = generate_response(model_client, system_instructions, user_query)
all_sentiments.append({
'tweet_id': i,
'model': model_name,
'sentiment': sentiment_value
})
print(f"Tweet {i} - Model {model_name} - Sentiment {sentiment_value}")
except Exception as e:
print("===================")
print("Exception occurred with model:", model_name, "| Tweet:", i, "| Error:", e)
exceptions += 1
time.sleep(sleep_time)
print("Total exception count:", exceptions)
return all_sentiments
Let's first call the predict_sentiment() function using the Llama3.1-405b model.
model = ("llama3.1-405b", "accounts/fireworks/models/llama-v3p1-405b-instruct")
all_sentiments = predict_sentiment(model, sleep_time=0)
results_df = pd.DataFrame(all_sentiments)
accuracy = accuracy_score(results_df['sentiment'],
dataset["airline_sentiment"].iloc[:len(results_df)])
print(f"Accuracy for {model[0]}: {accuracy}")
Output:
Total exception count: 0
Accuracy for llama3.1-405b: 0.78The above output shows that we achieved an accuracy of 78% using the Llama model.
Next, we will predict the sentiment of tweets using the DeepSeek R1 model.
model = ("deepseek-r1", "accounts/fireworks/models/deepseek-r1")
all_sentiments = predict_sentiment(model, sleep_time=4)
results_df = pd.DataFrame(all_sentiments)
accuracy = accuracy_score(results_df['sentiment'],
dataset["airline_sentiment"].iloc[:len(results_df)])
print(f"Accuracy for {model[0]}: {accuracy}")
Output:
Total exception count: 0
Accuracy for deepseek-r1: 0.75The above output shows that the DeepSeek R1 model achieves an accuracy of 75%, which is less than that of the Llama model.
After carefully observing the thinking steps of the DeepSeek R1 model, I noticed that it overthinks while solving simple tasks and often returns poor outputs compared to smaller, simpler models.
Next, we will compare DeepSeek and Llama models for text summarization.
DeepSeek R1 vs. Llama 3.1-405b for Text Summarization
We will use the News Articles Dataset to summarise text using the DeepSeek R1 and the Llama models.
The following script imports the dataset.
# Kaggle dataset download link
# https://github.com/reddzzz/DataScience_FP/blob/main/dataset.xlsx
dataset = pd.read_excel(r"/content/dataset.xlsx")
dataset = dataset.sample(frac=1)
print(dataset.shape)
dataset.head()Output:
Next, we will define the calculate_rouge() that accepts the human-generated and LLM-generated summaries and returns the ROUGE scores, a commonly used evaluation criteria for text summarization and machine translation problems.
# Function to calculate ROUGE scores
def calculate_rouge(reference, candidate):
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = scorer.score(reference, candidate)
return {key: value.fmeasure for key, value in scores.items()}
Finally, we will define the generate_summary() function, which generates the summaries of the first 20 articles in the dataset. You can pass the model name, path, and sleep time to this function.
The generate_summary() function returns average ROUGE scores for all the summaries.
def generate_summary(model, sleep_time=0):
results = []
model_name, model_client = model
i = 0
for _, row in dataset[:20].iterrows():
article = row['content']
human_summary = row['human_summary']
i = i + 1
print(f"Summarizing article {i} with model {model_name}")
system_role = "You are an expert in creating summaries from text"
user_query = f"Summarize the following article in 1150 characters. The summary should look like human created:\n\n{article}\n\nSummary:"
generated_summary = generate_response(model_client, system_role, user_query)
rouge_scores = calculate_rouge(human_summary, generated_summary)
results.append({
'model': model_name,
'article_id': row.id,
'generated_summary': generated_summary,
'rouge1': rouge_scores['rouge1'],
'rouge2': rouge_scores['rouge2'],
'rougeL': rouge_scores['rougeL']
})
time.sleep(sleep_time)
return results
Let's first generate summaries via the Llama3.1-405b model.
model = ("llama3.1-405b", "accounts/fireworks/models/llama-v3p1-405b-instruct")
results = generate_summary(model, sleep_time=0)
results_df = pd.DataFrame(results)
average_scores = results_df[['rouge1', 'rouge2', 'rougeL']].mean()
average_scores.head()
Output:
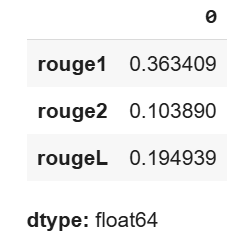
The above output shows the average ROUGE scores obtained via the Llama3.1-405b model.
Next, we will generate summaries via the DeepSeek R1 model.
model = ("deepseek-r1", "accounts/fireworks/models/deepseek-r1")
results = generate_summary(model, sleep_time=4)
results_df = pd.DataFrame(results)
average_scores = results_df[['rouge1', 'rouge2', 'rougeL']].mean()
average_scores.head()
Output:

The output shows that the DeepSeek R1 model achieves inferior ROUGE scores compared to the Llama model.
Conclusion
This article compares the original DeepSeek R1 model with the Llama3.1-405b model for text classification and summarization. The results show that the Llama3.1-405b model outperforms the DeepSeek R1 model for both text classification and summarization.
A careful insight into the thinking process of the DeepSeek R1 revealed that the model overthinks simple tasks such as text summarization and classification and, hence, achieves inferior performance compared to simple generative models.