This tutorial demonstrates how to build an AI agent that queries SQLite databases using natural language. You will see how to leverage the LangGraph framework and the OpenAI GPT-4o model to retrieve natural language answers from an SQLite database, given a natural language query.
So, let's begin without ado.
Importing and Installing Required Libraries
The following script imports the required libraries.
!pip install langchain-community
!pip install langchain-openai
!pip install langgraph
I ran the codes in this article on Google Colab[https://colab.research.google.com/], therefore I didnt have to install any other library.
The script below imports the required libraries into your Python application
import sqlite3
import pandas as pd
import csv
import os
from langchain_community.utilities import SQLDatabase
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool
from langchain_openai import ChatOpenAI
from langchain import hub
from langgraph.graph import START, StateGraph
from typing_extensions import Annotated
from IPython.display import Image, display
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')Creating a Dummy SQLite Database
We will perform question/answering using the SQLite database and LangGraph. The process remains the same for other database types.
We will create a dummy SQLite dataset using the Titanic dataset CSV file from Kaggle.
The following script converts the Titanic-Dataset.csv file into the titanic.db SQLite database.
dataset = pd.read_csv('Titanic-Dataset.csv')
dataset.head()Output:

import pandas as pd
import sqlite3
def csv_to_sqlite(csv_file_path, database_name):
try:
# Read the CSV file into a pandas DataFrame with headers
df = pd.read_csv(csv_file_path)
# Connect to SQLite database (or create it if it doesn't exist)
conn = sqlite3.connect(database_name)
# Use the CSV file name (without extension) as the table name
table_name = csv_file_path.split('/')[-1].split('.')[0]
# Write the DataFrame to the SQLite database with headers as column names
df.to_sql(table_name, conn, if_exists='replace', index=False)
# Close the connection
conn.close()
return f"Data from '{csv_file_path}' has been successfully stored in '{database_name}', table '{table_name}'."
except Exception as e:
return f "An error occurred: {e}"
# Example usage
csv_file = 'Titanic-Dataset.csv'
database = 'titanic.db'
result = csv_to_sqlite(csv_file, database)
print(result)
Output:
Data from 'Titanic-Dataset.csv' has been successfully stored in 'titanic.db', table 'Titanic-Dataset'.Next, we will print some of the characteristics of our dataset.
db = SQLDatabase.from_uri("sqlite:////content/titanic.db")
print(db.dialect)
print(db.get_table_info())
print(db.get_usable_table_names())
db.run("SELECT * FROM 'Titanic-Dataset' LIMIT 10;")Output:
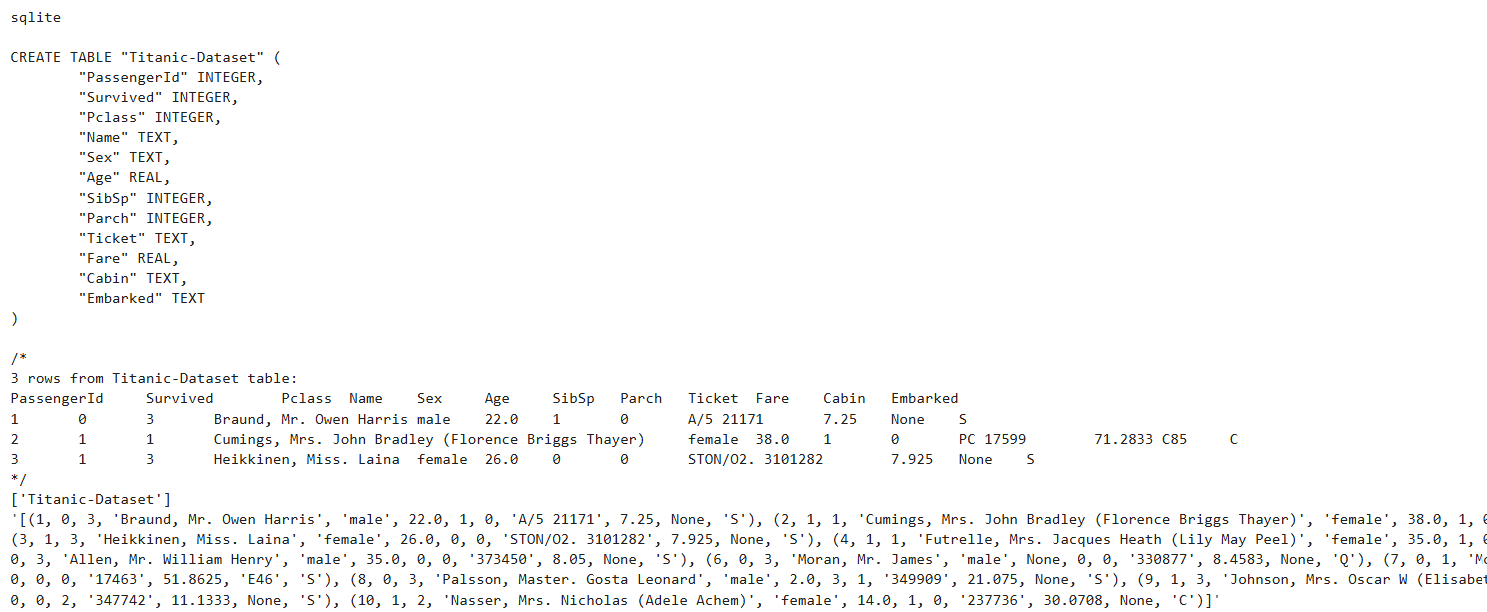
The output shows that the dataset type is SQL. The script uses the get_table_info() method to retrieve column names and sample data from 3 rows. Finally, we retrieve the first 10 rows from the dataset.
Next we will develop a LangGraph agent that converts natural language questions into SQL queries to retrieve data from the titanic.db SQLite database.
Developing a LangGraph Agent for Question/Answering Over SQL Data
A LangGrah agent consists of an agent state, nodes, and edges.
Let's create these entities for our question/answering agent.
Defining the Agent State and LLM
An agent stores shared information for all nodes and edges in the graph. To create an agent state, you must define a class containing attributes for the state. These attributes are shared among all the nodes and edges in an agent.
The following script defines a state for our agent. The question will store a user question, the query will store a question converted to an SQL query, the result will contain the response from the SQL query, and finally, the answer contains a natural language answer.
The script also defines the LLM we will use for question/answering.
from typing_extensions import TypedDict
class State(TypedDict):
question: str
query: str
result: str
answer: str
llm = ChatOpenAI(model="gpt-4o")Convert Natural Language Questions to SQL Query
We will first define a function that takes in a user question and converts it to an SQL query.
We will use a default prompt from the LangChain hub, which uses the database type and info to convert user questions to SQL queries. The following script displays the prompt.
from langchain import hub
query_prompt_template = hub.pull("langchain-ai/sql-query-system-prompt")
assert len(query_prompt_template.messages) == 1
query_prompt_template.messages[0].pretty_print()Output:

Next, we will define the structure for the output from our LLM model. We simply want our LLM to return a valid SQL query.
We also define the convert_question_to_query() function, which accepts the model state as a parameter, extracts the question text from the state, and converts the question to an SQL query using the LLM and prompt we defined earlier. We will use this method as the starting node of our graph.
class QueryOutput(TypedDict):
""" Generated SQL query."""
query: Annotated[str, ..., "Syntactically valid SQL query."]
def convert_question_to_query(state: State):
""" Generate SQL query to fetch information."""
prompt = query_prompt_template.invoke(
{
"dialect": db.dialect,
"top_k": 10,
"table_info": db.get_table_info(),
"input": state["question"],
}
)
structured_llm = llm.with_structured_output(QueryOutput)
result = structured_llm.invoke(prompt)
return {"query": result["query"]}
Let's test the convert_question_to_query() method by asking a simple question.
question = {"question": "How many male passengers are there in the dataset"}
query = convert_question_to_query(question)
print(query)Output:
{'query': 'SELECT COUNT(PassengerId) FROM "Titanic-Dataset" WHERE Sex = \'male\';'}The above output shows that the convert_question_to_query() function converted our question into a valid SQL query.
Execute SQL Queries
Next, we will define a function that takes in the query generated from the convert_question_to_query() function and executes it on the titanic.db instance using the QuerySQLDataBaseTool object.
def execute_query(state: State):
"""Execute SQL query."""
execute_query_tool = QuerySQLDataBaseTool(db=db)
return {"result": execute_query_tool.invoke(state["query"])}
result = execute_query(query)
print(result)Output:
{'result': '[(577,)]'}The above output shows that the LLM thinks we have 577 male passengers in our Titanic dataset.
Let's verify this number directly from the dataset CSV file.
dataset["Sex"].value_counts()Output:
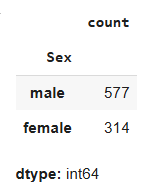
You can see that the total number of male passengers is 577.
Generate Final Response
Finally, we will define the generate_test() function, which uses the user question, the SQL query, and its result to compile a natural language answer to the user question.
def generate_answer(state: State):
""" Answer question using retrieved information as context."""
prompt = (
"Given the following user question, corresponding SQL query,"
"and SQL result, answer the user question.\n\n"
f'Question: {state["question"]}\n'
f'SQL Query: {state["query"]}\n'
f'SQL Result: {state["result"]}'
)
response = llm.invoke(prompt)
return {"answer": response.content}
Adding Nodes to LangGraph and Generating Response
We will define our LangGraph, which contains the convert_question_to_query, execute_query, and generate_answer functions as graph nodes in a sequence.
We set the convert_question_to_query node as the starting point of our graph.
Finally, we compile the graph and display its structure.
graph_builder = StateGraph(State).add_sequence(
[convert_question_to_query, execute_query, generate_answer]
)
graph_builder.add_edge(START, "convert_question_to_query")
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
Output:
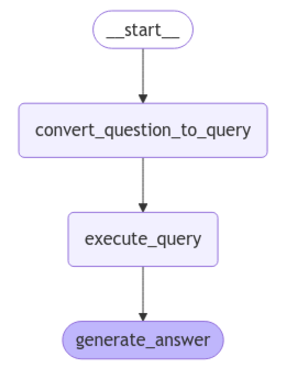
You can see the sequence of functions that will execute in our graph.
Let's test our graph.
We define the generate_stream_response() function, which takes the user question as a parameter value and uses the graph.stream() function to return the response of all the nodes in the graph.
def generate_stream_response(question):
for step in graph.stream(question, stream_mode="updates"):
print(step)
Let's ask a question from the generate_stream_response() function.
question = {"question": "How many male passengers are there in the dataset"}
generate_stream_response(question)Output:
{'convert_question_to_query': {'query': 'SELECT COUNT(PassengerId) AS MalePassengerCount FROM "Titanic-Dataset" WHERE Sex = \'male\';'}}
{'execute_query': {'result': '[(577,)]'}}
{'generate_answer': {'answer': 'There are 577 male passengers in the dataset.' }}The above output shows the output of all the nodes in our graph. You can see that the convert_question_to_query node returns a valid SQL query based on the input function. The execute_query node executes this query on the database and returns the result. Finally, the generate_answer node returns the answer in natural language.
Let's ask a slightly more complex question.
question = {"question": "What is the average age of male passengers?"}
generate_stream_response(question)Output:
question = {"question": "What is the average age of male passengers?"}
generate_stream_response(question)
{'convert_question_to_query': {'query': 'SELECT AVG(Age) AS AverageAge FROM "Titanic-Dataset" WHERE Sex = \'male\''}}
{'execute_query': {'result': '[(30.72664459161148,)]'}}
{'generate_answer': {'answer': 'The average age of male passengers is approximately 30.73 years.' }}The graph generated the correct answer. (You can verify it from the CSV file.)
Finally, if you are only interested in the final response, you can call the graph.invoke() method and retrieve the value of the answer attribute from the response.
final_answer = graph.invoke(question)
print(final_answer['answer'])Output:
The average age of male passengers is approximately 30.73 years.Conclusion
Retrieving data from databases using natural language queries is an important task. Large language models can simplify this task. In this article, you saw how to use the Python LangGraph module to create a smart AI agent that takes a user question as input, converts the question into an SQL query, and returns the response from an SQLite database. I encourage you to use the same technique for other database types, such as SQL Server and MySQL and see if it works for you.
