Introduction
I was working on a problem where I had to scrape tweets related to the T20 Cricket World Cup 2022, which is currently taking place in Australia.
I wanted tweets containing location names (cities) and the keyword “T20”. In the response, I want the user names of tweet authors, tweet texts, creation time, and the location keyword used to search the tweet. Finally, I wanted to create a Python Pandas Dataframe that contains these values in columns.
In this article, I will explain how you can return scrape tweets containing location information and how to store these tweets in a Pandas Dataframe.
Developers can scrape tweets from Twitter using the Twitter REST API. In most cases, the Twitter API returns tweet-type objects that contain various attributes for extracting tweet information. However, by default, the Twitter API doesn't return a Pandas Dataframe.
Simple Example of Scraping Tweets
You must sign up with Twitter Developer Account and create your API Key and Token to access the Twitter REST API. The official documentation explains signing up for the Twitter Developer Account.
I will use the Python Tweepy library for accessing the Twitter API. Tweepy is an unofficial Python client for accessing the Twitter API.
The following script demonstrates a basic example of Twitter scraping with the Python Tweepy library.
I use the search_all_tweets() function to search 100 English language tweets containing keywords Sydney and T20. I set a filter for removing retweets.
import pandas as pd
import os
import tweepy
bt = os.environ['twitter-bt']
client = tweepy.Client(bearer_token = bt,
wait_on_rate_limit= False)
location = "Sydney T20"
language = "lang:en "
no_tweet = "-is:retweet "
query = '"'+location+'" ' + language + no_tweet
tweets = client.search_all_tweets(query = query,
max_results=100)
tweets.dataYou can use the data attribute of the response object to print the returned tweets. You can access tweet text using the text attribute as shown below:
Output:

Scraping Tweets into Pandas DataFrames
Now you know how to scrape tweets with Tweepy, let’s scrape tweets with the following information and store them in a Pandas dataframe:
- Username of the tweet author.
- Tweet text.
- Creation time of the tweet.
Scraping Tweets with a Single Location
I will scrape tweets with the following filters:
- Location keywords, e.g.,
Sydney T20 - English language
- No Retweets
- Between October 01, 2022, to October 30, 2022.
In this case, I passed values for the tweet_fields, user_fields, and expansions attributes of the search_all_tweets() function. These attributes extract tweet creation time and user information, e.g., username.
location = "Sydney T20"
language = "lang:en "
no_tweet = "-is:retweet "
start_time = '2022-10-01T00:00:00Z'
end_time = '2022-10-30T00:00:00Z'
query = '"'+location+'" ' + language + no_tweet
tweets = client.search_all_tweets(query = query,
tweet_fields=['created_at'],
user_fields=['username'],
expansions=['author_id'],
start_time=start_time,
end_time=end_time,
max_results=100)
tweets.includes['users']In addition to the data attribute, which contains tweet information, you can retrieve user information using the tweets.includes[‘users’] list.
Output:
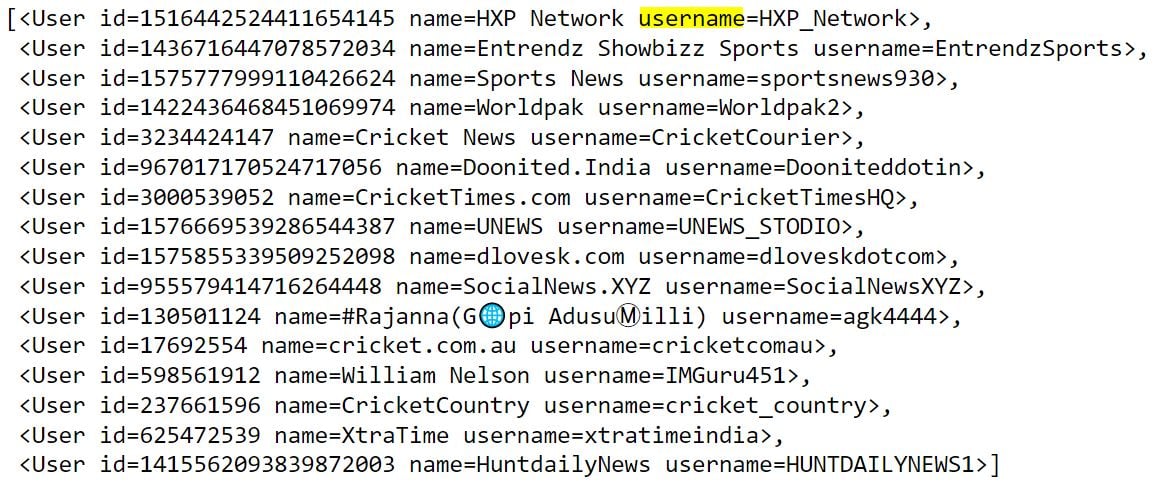
You can iterate through lists of tweet data and user data to extract user name, tweet, text, and tweet creation time and append these values to Python lists.
Finally, you can create a Pandas dataframe using these lists. Here is an example script:
user_name = []
text = []
date_time = []
for tweet, user in zip(tweets.data, tweets.includes['users']):
text.append(tweet.text)
date_time.append(tweet.created_at)
if user is not None:
user_name.append(user.name)
df = pd.DataFrame(list(zip(user_name, text, date_time)),
columns =['User', 'Text', 'Date Time'])
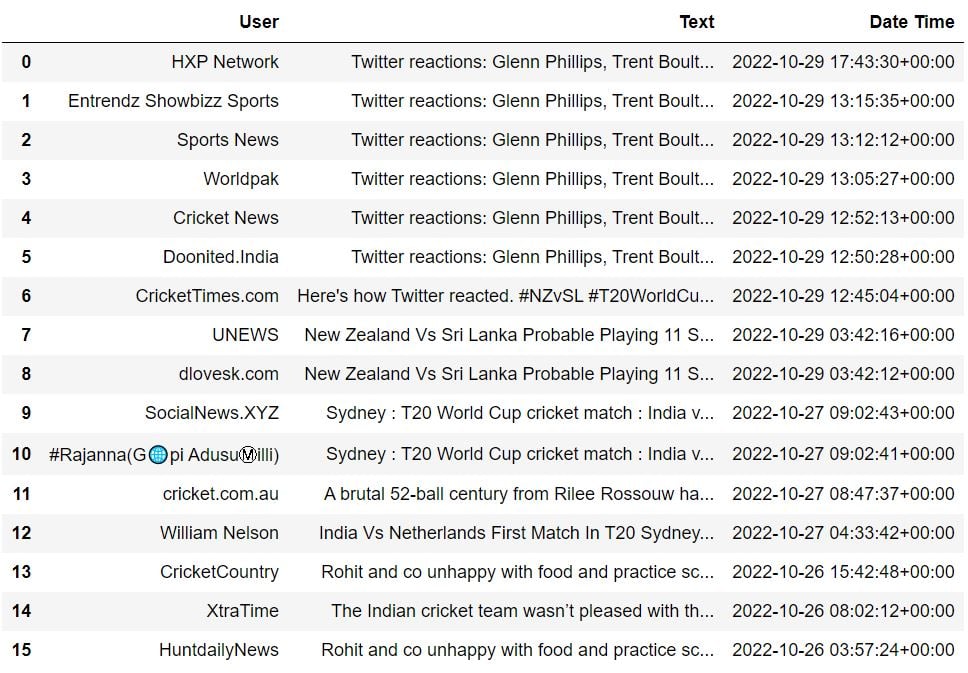
df.head(20)Output:
Scraping Tweets with Multiple Locations
Since I wanted to extract tweets by multiple location keywords, I defined a Python function that accepts a list of locations, along with the start and end date of tweets. The function iterates through all the locations and appends the extracted tweet information in Python lists.
The get_location_tweets() function in the following script returns a Pandas dataframe containing the tweet text, the tweet author's username, the tweet's creation time, and the location keyword that parameterizes the tweet search.
import time
def get_location_tweets(loc_list, st, et):
user_name = []
text = []
date_time = []
loc_keyword = []
i = 0
for loc in loc_list:
i = i + 1
location = loc + " T20"
language = "lang:en "
no_tweet = "-is:retweet "
start_time = st
end_time = et
query = '"'+location+'" ' + language + no_tweet
tweets = client.search_all_tweets(query = query,
tweet_fields=['created_at'],
user_fields=['username'],
expansions=['author_id'],
start_time=start_time,
end_time=end_time,
max_results=100)
user_name = []
text = []
date_time = []
for tweet, user in zip(tweets.data, tweets.includes['users']):
text.append(tweet.text)
date_time.append(tweet.created_at)
if user is not None:
user_name.append(user.name)
loc_keyword.append(loc)
time.sleep(3)
df = pd.DataFrame(list(zip(user_name, text, date_time, loc_keyword)),
columns =['User', 'Text', 'Date Time', 'Loc Keyword'])
return dfThe following script calls the get_location_tweets() function to search for tweets containing either Sydney, Perth, Melbourne and the keyword T20.
loc_list = ["Sydney", "Perth", "Melbourne"]
start_time = '2022-10-01T00:00:00Z'
end_time = '2022-10-30T00:00:00Z'
locations_df = get_location_tweets(loc_list, start_time, end_time)
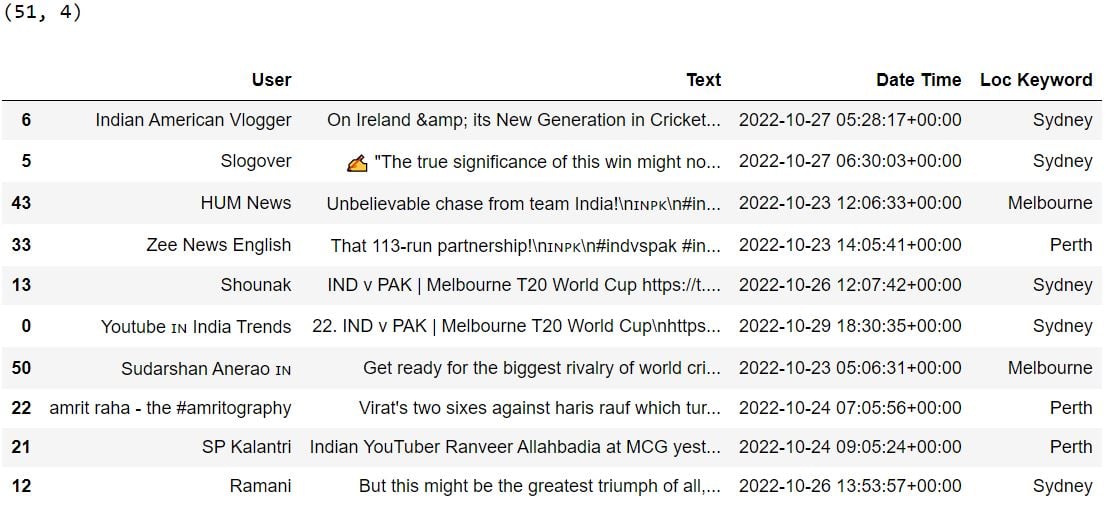
print(locations_df.shape)
locations_df.sample(frac=1).head(10)Output:
Extracting tweets using Twitter API is straightforward. However, storing desired information from tweets in a data structure, e.g., a Pandas dataframe, is tricky. In this tutorial, I explained how you could scrape tweets using Twitter API and store them in a Pandas Dataframe in your desired format.